

Comparativa Llama-3 y Phi-3 utilizando RAG
Hoy os comparto instrucciones de como montar Llama-3 y Phi-3 en la nube para poder usar ambos a través de un interfaz gráfico amigable.
Plataforma para la comparativa
Esto es lo que uso habitualmente para montar sistemas de IA en la nube (y que tengo comprobado que funciona):
- Ollama para servir localmente un LLM (Llama-3): WEB y Github.
- Llama_Index para la orquestación. LlamaIndex conecta LLMs con tus datos. WEB y Github.
- Streamlit para construir la interfaz de usuario. Streamlit es un framework en Python de código abierto para que los científicos de datos y los ingenieros de IA/ML desarrollen aplicaciones de datos dinámicas en tan solo unas líneas de código: WEB.
- LightningAI para el desarrollo y alojamiento. La plataforma de desarrollo de IA: de la idea a la IA en un abrir y cerrar de ojos: WEB.
Arquitectura
La arquitectura que se presenta a continuación ilustra algunos de los componentes clave y cómo interactúan entre sí.
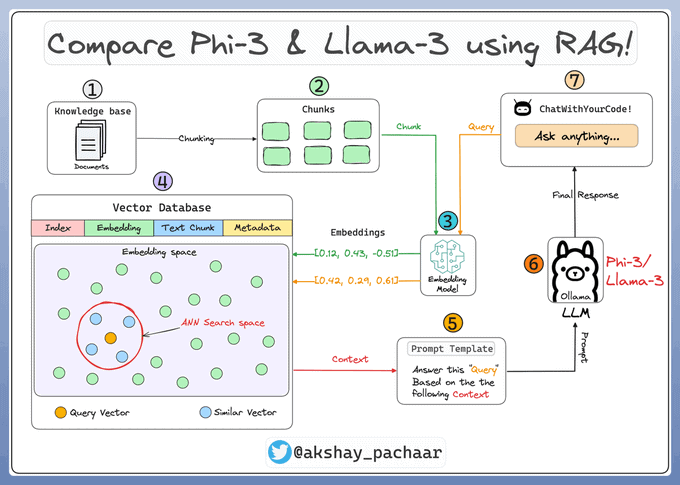
Carga de la base de conocimientos (pasos 1 y 2)
Una base de conocimientos es una colección de información relevante y actualizada que sirve de base para RAG. En nuestro caso son los documentos almacenados en una carpeta.
Así los puedes cargar como objetos documento en LlamaIndex:

El modelo de inserción (paso 3)
La inserción es una representación significativa del texto en forma de números.
El modelo se encarga de crear inseciones para los trozos de documentos y las consultas de los usuarios.

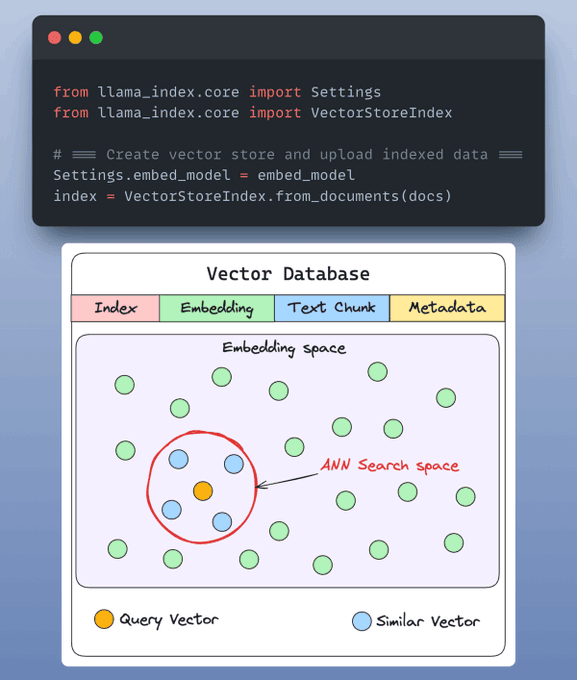
Indexación y almacenamiento (paso 4)
Las inserciones creadas por el modelo se guardan en un almacén de vectores que ofrece una rápida recuperación y búsqueda de similitudes mediante la creación de un índice sobre nuestros datos.
Por defecto, LlamaIndex proporciona un almacén vectorial en memoria que es ideal para la experimentación rápida.
Crear una plantilla de instrucciones (paso 5)
Una plantilla personalizada de prompt se utiliza para refinar la respuesta de LLM e incluir también el contexto:

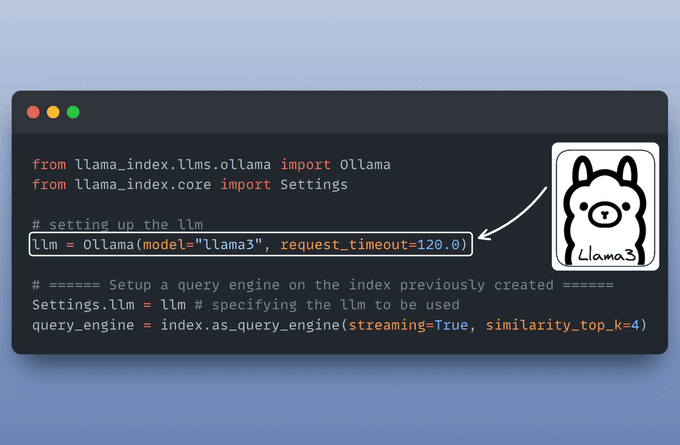
Configuración de un motor de consulta (pasos 6 y 7)
El motor de consulta toma una cadena de consulta y la utiliza para obtener el contexto relevante y luego envía ambos como un prompt al LLM para generar una respuesta final en lenguaje natural.
A continuación se explica cómo configurarlo:
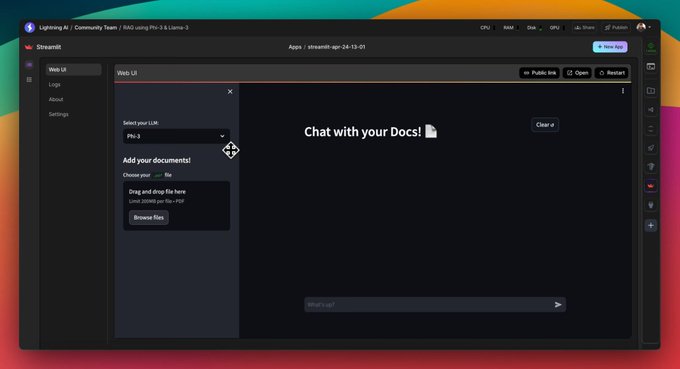
La interfaz de Chat (paso 8)
Creamos una interfaz de usuario utilizando Streamlit para proporcionar una interfaz de chat para nuestra aplicación RAG.
Compara los dos modelos con Lightning.AI en la nube
Esto está montado con LightningAI ⚡️ Studio.
Para probarlo, clona el estudio completo con código y entorno. El ejemplo en inglés está aquí: Compare Llama-3 and Phi-3 using RAG. Yo lo tengo traducido y modificado en castellano pero es un «work in progress» que modifico 20 veces al día.
Antes de ejecutar nada, mata todos los procesos
Nota: Cada vez que ejecutes la aplicación, asegúrate de que la GPU está libre e intenta matar otros procesos que utilicen la GPU si es necesario.
Dentro de tu terminal haz lo siguiente:
# obtener identificadores de proceso utilizando la GPU
nvidia-smi
# matar un proceso
kill -9 process_id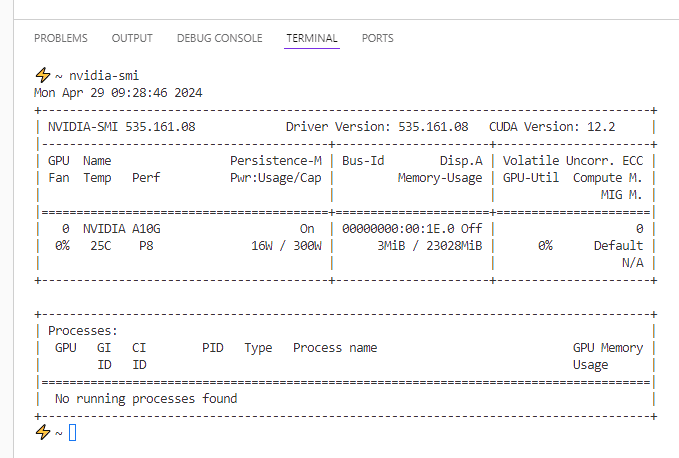
Interfaz de usuario de Lightning.AI
¿Dónde está el código? En el archivo main.ipynb
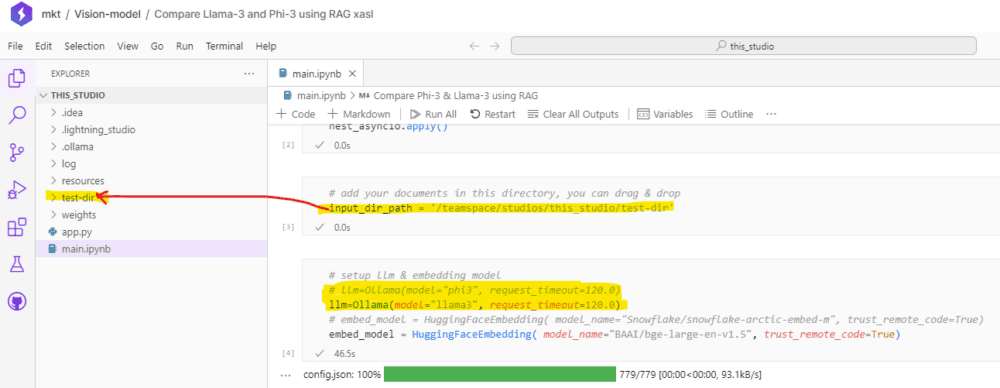
Ejecutamos el modelo
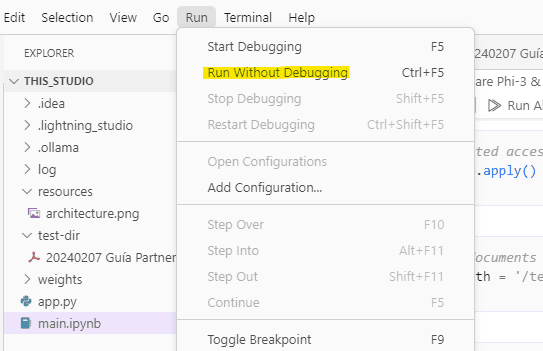
Ejecutamos Streamlit para tener una interfaz amigable
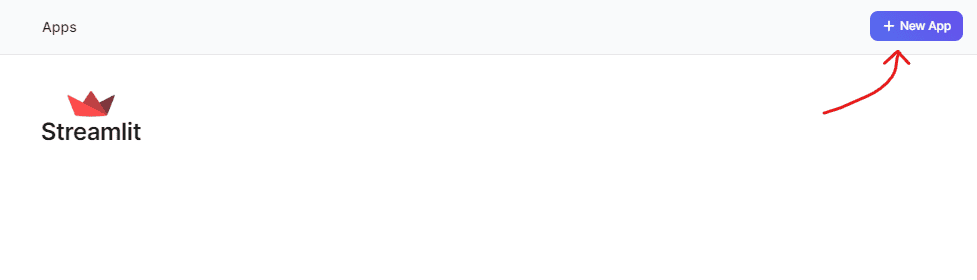
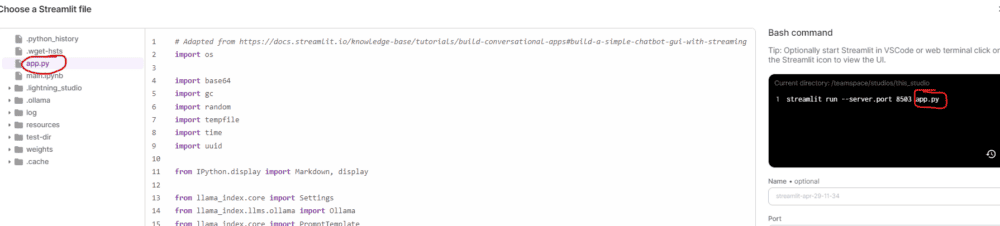
Y ya podemos chatear con los modelos
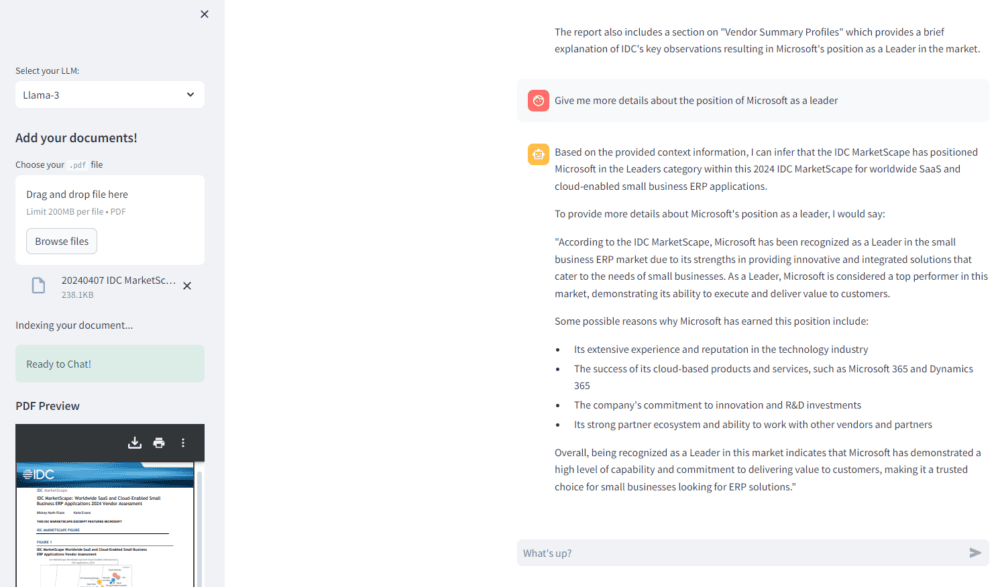
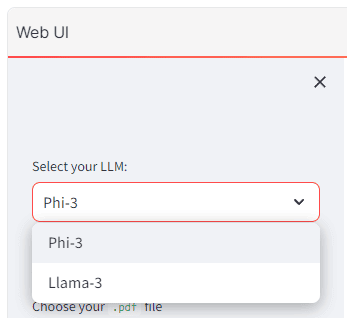
Cambiando el modelo se pueden comparar las respuestas:
Información basada en la publicación de Twitter/X de Akshay Pachaar (AI Engineering @LightningAI) y el modelo «Compare Llama-3 and Phi-3 using RAG» publicado en Lightning.ai.


