La mayor interrupción de TI hasta la fecha
Unos mil millones de ordenadores Windows están bloqueados debido a un error de actualización del sistema de seguridad CrowdStrike.
Esto afecta aeropuertos, bancos, servicios de emergencia, tiendas, básicamente todos los ordenadores con Microsoft Windows que usen CrowdStrike.
Y será la mayor interrupción de TI de la historia. El destacado consultor de seguridad Troy Hunt dice que «esta será la mayor interrupción de TI hasta la fecha» y «esto es básicamente lo que nos preocupaba del ‘efecto 2000’, excepto que esta vez sucedió«.
No se trata sólo de que un servicio en línea deje de funcionar durante unas horas. Todos los ordenadores afectados deben reiniciarse en modo de fallo y se les debe eliminar manualmente un controlador.
La mayoría de los ordenadores de empresa no permiten a sus empleados hacerlo por sí mismos. Incluso si tuviesen permisos, imagina a cada uno de los empleados con un coeficiente intelectual de dos dígitos tratando de manejar una tarea medianamente compleja cuando muchos ni siquiera saben lo que es un archivo.

¿Qué ha pasado?
En primer lugar aclarar que el error no ha sido de Microsoft, al menos no en el sentido estricto.
La nube de Microsoft, Azure, usa utiliza un EDR para la protección de la infraestructura.
¿Qué es un EDR?
Un EDR (Endpoint Detection and Response) es una solución de ciberseguridad que se centra en la detección, análisis y respuesta a amenazas en los endpoints (dispositivos finales) de una red, como computadoras, laptops, y dispositivos móviles. A continuación se detallan sus tres principales características y funciones:
- Monitoreo Continuo: Un EDR supervisa continuamente la actividad en los endpoints para identificar comportamientos sospechosos o anómalos que puedan indicar una posible amenaza.
- Detección de Amenazas: Utiliza técnicas avanzadas, como el análisis de comportamiento, machine learning y firmas de amenazas conocidas, para detectar actividades maliciosas.
- Respuesta Automática: Al detectar una amenaza, un EDR puede tomar medidas automáticas para contenerla, como aislar el endpoint afectado de la red, detener procesos maliciosos o eliminar archivos dañinos.
En resumen, un EDR es una herramienta crucial en la estrategia de ciberseguridad de una organización, ya que ayuda a proteger los dispositivos finales contra una amplia gama de amenazas, ofreciendo una respuesta rápida y efectiva ante incidentes de seguridad.
La actualización del EDR de Azure ha provocado el incidente
La empresa que se encarga de esto en Azure se llama Crowdstrike. Este software necesita actualizarse para ser efectivo y seguro. Y en una actualización que se ha llevado a cabo durante el día de hoy… alguien ha metido la pata.
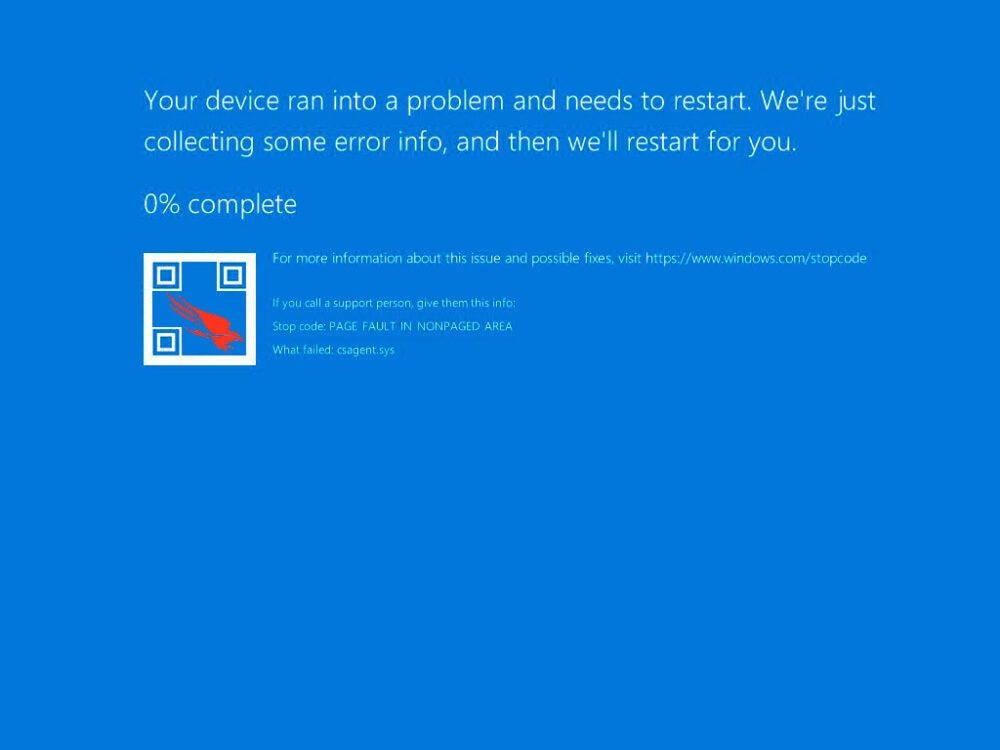
Había un error en el código, nadie lo ha detectado y se ha subido a producción. Y el fallo en cuestión hace que los equipos se bloqueen a nivel de Kernel, el cerebro del equipo.
A esto lo llamamos BSOD (Blue Screen Of Death). El temido pantallazo azul.
Y ahora esos ordenadores se han convertido en pisapapeles. ¿Por qué es esto tan grave? Pues es tan grave porque usamos ordenadores para todo. Control de vuelos en aerolíneas, banca, supermercados, hasta máquinas expendedoras modernas.
¿Y cómo se va a solucionar esto?
Pues de forma manual. La empresa, Crowdstrike, ya ha dado marcha atrás al cambio, pero los equipos bloqueados eso les da exactamente igual. Remotamente no se puede hacer nada.
Se debe eliminar un archivo, el que está causando los bloqueos, en todos los equipos afectados UNO A UNO Y A MANO.
Como los equipos corporativos suelen estar cifrados con Bitlocker esto es un problema enorme porque para eliminar el archivo hay que tener la clave de encriptación.
Estamos hablando de una solución lenta, muy lenta y muy cara. Y cada minuto que pasa son millones en pérdidas. Aerolíneas paradas, bancos sin funcionar correctamente, supermercados totalmente parados y miles de industrias afectadas más.
Aunque la mayoría podemos estar tranquilos porque no afecta al 99,9% de equipos que tenemos en casa.
¿Cómo solucionar el pantallazo azul de CrowdStrike?
El archivo que ocasina el problema es «C-00000291.sys»:
- El archivo de canal «
C-00000291.sys» con fecha de 0527 UTC o posterior es la versión revertida (buena). - El archivo de canal «
C-00000291.sys» con fecha y hora de 0409 UTC es la versión problemática.
Nota: Es normal que haya varios archivos «C-00000291*.sys» en el directorio de CrowdStrike – siempre que uno de los archivos de la carpeta tenga una marca de tiempo de 0527 UTC o posterior, ése será el contenido activo.
Solución al pantallazo azul en ordenadores
Reinicia Windows para darle la oportunidad de descargar el archivo sin el error. Si el ordenador sigue fallando, entonces:
- Arranca Windows en modo seguro o en el entorno de recuperación de Windows.
- A ser posible conectado a internet por cable (en lugar de WiFi) y utilizando el modo seguro con funciones de red.
- Navega al directorio
%WINDIR%\System32\drivers\CrowdStrike - Localiza el archivo «
C-00000291*.sys» y elimínalo. - Arranque el sistema normalmente.
Nota: Los hosts encriptados con Bitlocker requieren la clave de recuperación para poder acceder a la eliminación del archivo.
Solución con un script publicado en Github
La comunidad ha publicado un script automatizado para Windows que arregla el error de Crowdstrike.
CrowdStrike-rollback.ps1 es un script de PowerShell diseñado para automatizar el proceso de eliminación de un archivo específico relacionado con CrowdStrike que puede estar causando problemas en tu sistema Windows. Este script debe ejecutarse en Modo Seguro o en el Entorno de Recuperación de Windows.
- Asegúrate de tener permisos de administrador en el sistema donde se ejecutará el script.
- Guarda el script en un archivo llamado
CrowdStrike-rollback.ps1.
- Reinicia el sistema y entra en Modo Seguro o en el Entorno de Recuperación de Windows.
- Para entrar en Modo Seguro, mantén presionada la tecla Shift mientras haces clic en «Reiniciar» y luego selecciona:
- «Solucionar problemas»
- «Opciones avanzadas»
- «Configuración de inicio»
- «Reiniciar»
- Después, selecciona la opción para Modo Seguro.
- Para entrar en el Entorno de Recuperación de Windows, sigue un proceso similar y selecciona:
- «Solucionar problemas»
- «Opciones avanzadas»
- «Símbolo del sistema».
- Abre PowerShell con privilegios de administrador.
- Navega al directorio donde se guardó el script.
- Ejecuta el script con el siguiente comando:
.\CrowdStrike-rollback.ps1
Herramienta de recuperación de Microsoft
Como seguimiento al problema del agente CrowdStrike Falcon que afecta a clientes y servidores Windows, Microsoft ha publicado una herramienta de recuperación actualizada con dos opciones de reparación para ayudar a los administradores de TI a acelerar el proceso de reparación. La herramienta de recuperación firmada de Microsoft puede encontrarse en el Centro de descargas de Microsoft. Las dos opciones de reparación son las siguientes
- Recuperar desde WinPE – esta opción produce medios de arranque que ayudarán a facilitar la reparación del dispositivo.
- Recuperar desde modo seguro – esta opción produce medios de arranque para que los dispositivos afectados puedan arrancar en modo seguro. A continuación, el usuario puede iniciar sesión utilizando una cuenta con privilegios de administrador local y ejecutar los pasos de reparación.
La herramienta se puede descargar en el Centro de Descargas de Microsoft: Microsoft Recovery Tool.
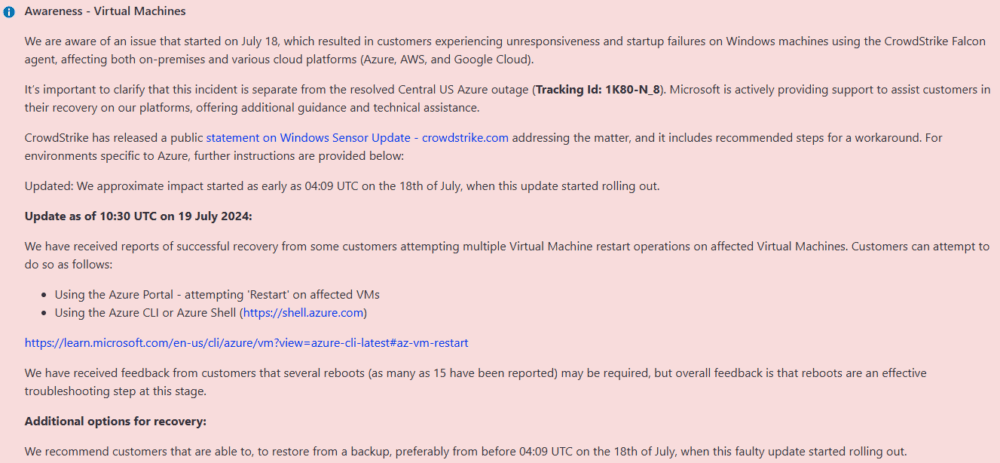
Solución al pantallazo azul en Azure
Según Microsoft una forma de solucionar el pantallazo azul es reinicar varias veces las máquinas virtuales afectadas. Los clientes pueden intentar hacerlo de la siguiente manera:
- Usando el Portal Azure – intentando ‘Reiniciar’ en las Máquinas Virtuales afectadas.
- Usando Azure CLI o Azure Shell.
Microsoft ha recibido comentarios de clientes que han necesitado hasta 15 reinicios hasta que el pantallazo azul ha desaparecido.
Esto parece debido a que el archivo afectado («C-00000291.sys») tiene dependencias y en cada reinicio se van actualizando poco a poco hasta el pantallazo azul; por lo que son necesarios varios reinicios hasta recuperar el ordenador.
Un poco de humor y ánimos para los técnicos
🇫🇷 Se ha caído Windows.
🇩🇪 Se ha caído Windows.
🇺🇲 Se ha caído Windows.
🇬🇧 Se ha caído Windows.
🇧🇻 Se ha caído Windows.
🇸🇪 Se ha caído Windows.
🇪🇦 Bueno, pues bajamos un rato al bar, si lo arregláis dadnos un toque y si no buen finde a todos.
¿Pero cómo ha podido pasar?
Lo que importa es que este incidente expone prácticas de prueba y despliegue negligentes, y eso es todo lo que importa.
Las pruebas están muy bien pero nunca lo pillan todo, no pueden y por eso cuando estás desplegando una actualización automática que puede dejar un ordenador como un pisapapeles, la despliegas muy lentamente a lo largo de varios días, empezando con una pequeña muestra aleatoria («canary testing«).
Si se rompe algo en la muestra aleatoria (pequeña), se detiene el despliegue. Esta ha sido la práctica habitual durante décadas.
- ¿De dónde nace el Canary Testing? Los canarios se empezaron a usar en las minas de carbón en 1911, para detectar monóxido de carbono y otros gases tóxicos antes de que dañen a los humanos. Felizmente esta práctica terminó en 1986.
- Canary Testing en pruebas de software: Consiste en exponer el nuevo código que has desarrollado a un pequeña parte del sistema, a un pequeño grupo de usuarios en producción, con la finalidad que si se encuentra un error tenga un impacto mínimo y sea más fácil revertirlo a su estado estable. Aquí los usuarios son inconscientes que se encuentran usando nuevo código, permitiendo ver como nuestro nuevo código responde al mundo real.
Y en el caso de CrowdStrike la actualización se desplegó de golpe en vez de lentamente. Cuando un software puede dejar u ordenador inservible si falla, hay que desplegarlo lentamente, simplemente no hay excusa para no hacerlo.
¿Cuál ha sido el error que ha provocado esto?
Aunque el error en si no sea lo relevante, sino que el problema ha sido el despliegue masivo sin comprobar si había problemas, si que puede ser interesante conocer el fallo que ha provocado este desastre.
CrowdStrike al parecer estaba leyendo un archivo de datos erróneo e intentando acceder a memoria no válida.
Este fallo global fue una bomba de dos partes. El detonador aparentemente, NO era nuevo.. estaba PRE-INSTALADO.
Contrariamente a las sospechas iniciales, CrowdStrike NO lanzó un controlador defectuoso, el controlador defectuoso YA existía en Mac, Linux Y Windows, probablemente desde hace meses o años.
Este error tiene dos partes. Y lo que necesitaba eran datos erróneos para activarlo y esto pasó con la actualización del jueves pasado.
Por lo general, se considera que el despliegue de nuevos archivos de datos en los ordenadores es seguro. Al fin y al cabo, los datos no contienen instrucciones ejecutables para la CPU.
Por lo tanto, no pasan por el mismo proceso de revisión de código que un nuevo código ejecutable.
Esta actualización de datos, debido a sus supuestas implicaciones de baja seguridad, pudo ser introducida en todos los equipos Windows que ejecutaban CrowdStrike, sin consentimiento y sin notificación.
Y por cierto, esta misma bomba de relojería aparentemente existe en Linux y MacOS. Simplemente no fueron objeto de esta actualización de datos, por lo que no se quedaron colgados.
¿Y por qué no se detectó este error de software mediante comprobaciones automáticas en Microsoft? Este código está leyendo datos, interpretándolos como posiciones de memoria válidas, e intentando leerlos.
Explicación oficial de CrowdStrike publicada en su blog
Esto es la explicación oficial de CrowdStrike publicada en su blog:
¿Qué ha ocurrido? El 19 de julio de 2024 a las 04:09 UTC, como parte de las operaciones en curso, CrowdStrike publicó una actualización de la configuración de los sensores para los sistemas Windows. Las actualizaciones de la configuración de los sensores forman parte de los mecanismos de protección de la plataforma Falcon. Esta actualización de la configuración desencadenó un error lógico que provocó un bloqueo del sistema y una pantalla azul (BSOD) en los sistemas afectados.
La actualización de la configuración de los sensores que provocó el bloqueo del sistema se corrigió el viernes 19 de julio de 2024 a las 05:27 UTC.
Este problema no es el resultado de un ciberataque ni está relacionado con él.
Impacto: Los clientes que ejecutan Falcon sensor para Windows versión 7.11 y superior, que estuvieron online entre el viernes 19 de julio de 2024 04:09 UTC y el viernes 19 de julio de 2024 05:27 UTC, pueden verse afectados.
Los sistemas que ejecutan Falcon sensor para Windows 7.11 y superiores que descargaron la configuración actualizada entre las 04:09 UTC y las 05:27 UTC – eran susceptibles de sufrir un fallo del sistema.
Introducción a los archivos de configuración
Los archivos de configuración mencionados anteriormente se denominan «archivos de canal» y forman parte de los mecanismos de protección del comportamiento utilizados por el sensor Falcon. Las actualizaciones de los archivos de Canal son una parte normal del funcionamiento del sensor y se producen varias veces al día en respuesta a nuevas tácticas, técnicas y procedimientos descubiertos por CrowdStrike. No se trata de un proceso nuevo; la arquitectura ha estado en funcionamiento desde la creación de Falcon.
Detalles técnicos
En los sistemas Windows, los archivos de canal residen en el siguiente directorio:
C:\Windows\System32\drivers\CrowdStrike\y tienen un nombre de archivo que empieza por «C-». A cada archivo de canal se le asigna un número como identificador único. El archivo de canal impactado en este evento es el 291 y tendrá un nombre de archivo que comienza con «C-00000291-» y termina con una extensión .sys. Aunque los archivos de canal terminan con la extensión SYS, no son controladores del núcleo.
El archivo de canal 291 controla cómo Falcon evalúa la ejecución de named pipelines en sistemas Windows. Las «canalizaciones con nombre» se utilizan para la comunicación normal, entre procesos o entre sistemas en Windows.
La actualización que se produjo a las 04:09 UTC se diseñó para atacar las named pipelines maliciosas observadas recientemente y utilizadas por marcos C2 comunes en ciberataques. La actualización de la configuración desencadenó un error lógico que provocó la caída del sistema operativo.
Archivo de canal 291
CrowdStrike ha corregido el error lógico actualizando el contenido del archivo de canal 291. No se implementarán cambios adicionales en el archivo de canal 291 aparte de la lógica actualizada. Falcon sigue evaluando y protegiendo contra el abuso de named pipelines.
Esto no está relacionado con los bytes nulos contenidos en el archivo de canal 291 ni en ningún otro archivo de canal. Los sistemas que ejecutan Linux o macOS no utilizan el archivo de canal 291 y no se han visto afectados.
Análisis de la causa
Se está intentando entender por parte de CrowdStrike cómo se produjo este problema y se está realizando un análisis exhaustivo de la causa para determinar cómo se produjo este fallo lógico.
Análisis de esta información por el CEO de ExploitChance
Comentarios de Hugo Vázquez Caramés (CEO & Co-Founder at ExploitChance) sobre la información oficial de CrowdStrike:
1) Publicación del fabricante CrowdStrike donde, nos dice que: «Although Channel Files end with the SYS extension, they are not hashtag#kernel hashtag#drivers.» y luego nos dice que: «The configuration update triggered a logic error that resulted in an operating system crash.«.
A ver: un BSOD no se genera por un error en el espacio de usuario, es un error en el código que se ejecuta en el kernel. Desviar la atención de que el fichero SYS no es un driver no es lo correcto. El BSOD se produce por un error en un driver de CrowdStrike (csagent.sys). Pero este error no se producía hasta que se actualizó ese fichero SYS, es decir que el driver de CrowdStrike tenía rutinas que dependían de «contenido» de un fichero externo al driver. ¿Por qué eso? Pues para ahorrar tiempo. Certifico el driver y luego actualizo algo que NO es un driver, así que me ahorro el proceso de certificación de Microsoft.
2) CrowdStrike programa drivers de kernel en C/C++. No juzgo eso, para gustos colores. Pero tiene sus riesgos (de ahí que existan las certificaciones de drivers por parte de Microsoft, para no liarla parda)
3) Si unimos los dos puntos anteriores lo que tenemos es que CrowsStrike por una parte encontró una forma de «bypasear» los controles de calidad de Microsoft y por otra parte programa sus drivers en C/C++. Lo siento mucho, pero no me parece una buena idea, es legal, pero no es lo correcto, te la juegas muchísimo.
Nadie podrá obligarme a pensar o decir que esto es buena praxis. Lo honesto sería salir a la palestra y decir que hay un fallo seguridad en el diseño. Lo que pasa en Las Vegas se queda en las Vegas, pues lo que se ejecuta en el kernel… debería quedarse en el kernel, y no depender de «entes» externos fuera de control (el infame .SYS), no certificable, no auditable, etc. Es una barbaridad de dimensiones épicas y simplemente hay que admitirlo, corregir y ya está.
La maquinaria defensiva corporativa se ha puesto en marcha y están empezando a intentar desviar la atención del problema real (código defectuoso en el kernel de Windows que llega a producción a escala mundial) mareando la perdiz con el nombre del tipo de bug… Seguro que todos los que estén delante del pantallazo azul están muy preocupados por ese detalle.
Hugo Vázquez Caramés (CEO & Co-Founder at ExploitChance) en LinkedIn
La firma de los drivers por parte de Microsoft y este incidente
Esta información de Sergio de los Santos («Head of Innovación en Telefónica Tech.») me parece súper interesante por lo que la he incorporado aquí.
Microsoft testea todos los drivers a través del Hardware Lab Kit, y si son válidos, los firma. Este es el certificado que firmaba el driver principal de CrowdStrike en mayo:
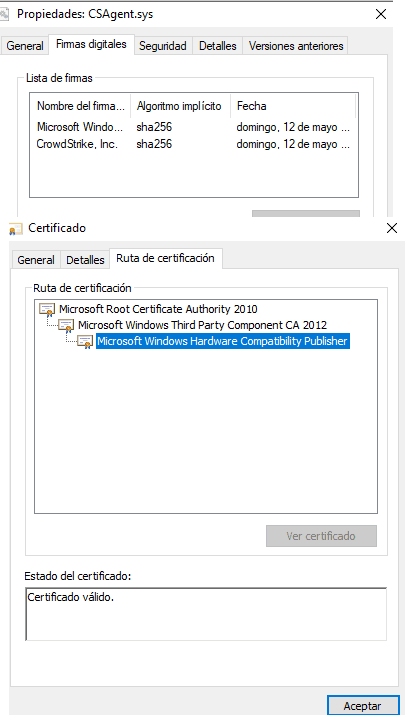
Esto no garantiza un driver perfecto pero sí suficientemente bueno y es altamente improbable que falle. ¿Por qué ha fallado entonces? Porque CrowdStrike se alimenta dinámicamente de lo que parecían otros drivers. Unos tales C-00000291-00000000-0000003X.sys. Que por dentro son así:
A pesar de la extensión SYS, no están firmados. Aunque no están documentados, parecen “alimento” dinámico para el driver firmado. Configuración, modificaciones… Así el driver puede actualizarse a menudo pero sin pasar por el proceso de firma que tardaría semanas.
Se dice que uno de esos ficheros .SYS que no son drivers, se distribuyó con 40k de caracteres nulos. Fue leído por el driver, no entendió nada, y en el contexto del kernel, cualquier sistema operativo se detiene por completo ante estas circunstancias por total inconsistencia.
¿Por qué Windows no se recupera de esto solo reiniciando o en remoto? Por ELAM (early launch anti malware). Windows, muy al principio del arranque carga los EDR firmados para supervisar el propio arranque y evitar rootkits. Como el EDR estaba corrupto, lo demás es historia.
Los términos y condiciones de CrowdStrike
8.2: Crowdstrike se compromete a operar de manera profesional de acuerdo con las normas del sector.
8.4: Crowdstrike hará todo lo posible por solucionar los problemas notificados. Si no puede, se le reembolsará lo que quede de su suscripción.
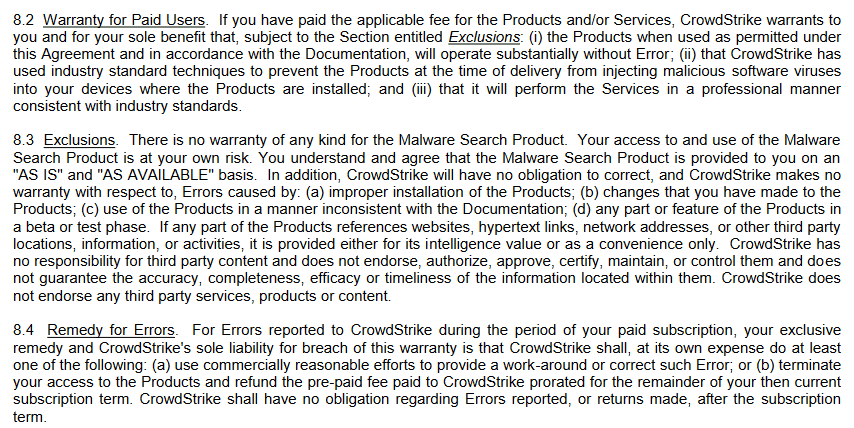
8.6: No hay garantía de que el producto proteja con éxito todas las amenazas, si aún así algo destruye su sistema, Crowdstrike no se hace responsable.
8.7: El producto puede tener errores, no hacer nada o no funcionar en absoluto y no hay nada que se pueda decir al respecto.

10: Cualesquiera que sean los daños derivados del uso del producto, corren de su cuenta. Incluso si CrowdStrike podría haberlo evitado.
Nunca utilice el producto en entornos sensibles, como sistemas de navegación aérea, instalaciones nucleares, etc.

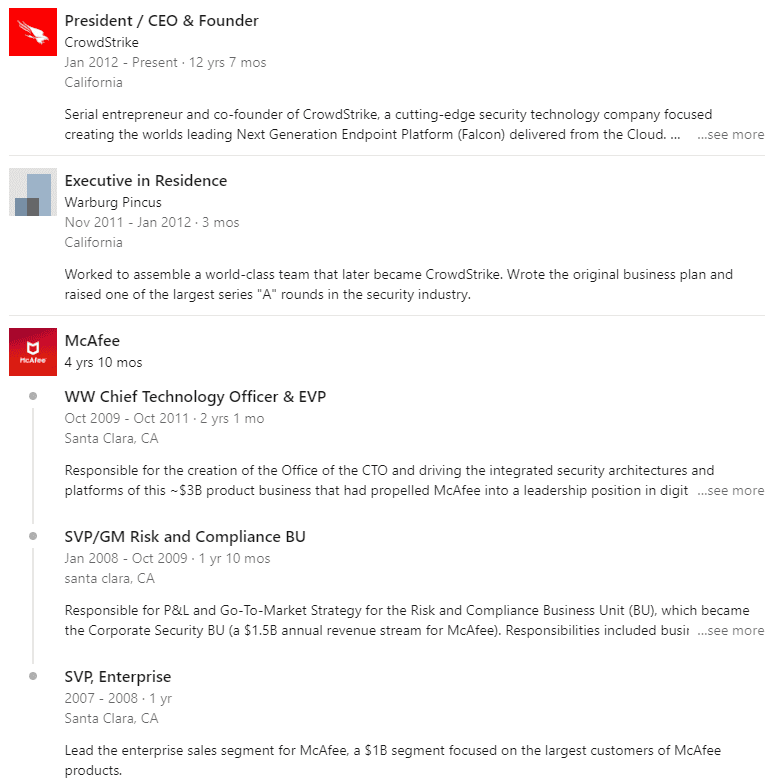
Curiosidad: ¿Quién es el CEO de CrowdStrike?
Para quienes no lo recuerden, en 2010 McAfee tuvo un fallo colosal con Windows XP que hizo caer buena parte de Internet. El hombre que era el director de tecnología de McAfee en ese momento es ahora el CEO de Crowdstrike. El incidente de McAfee costó tanto dinero que acabó vendiéndose a Intel.
Información de la solución al problema publicada por CrowdStrike: «Statement on Falcon Content Update for Windows Hosts – crowdstrike.com«. Pantallazo azul del hilo de Twitter/X. Explicación del error del hilo de Twitter/X de Zach Vorhies. Explicación de cómo ha podido pasar en el blog de CrowdStrike: «Technical Details: Falcon Content Update for Windows Hosts«. Publicación en Twitter/X de Sergio de los Santos sobre el testeo de los drivers por parte de Microsoft. Herramienta de recuperación de Microsoft actulizada: «New Recovery Tool to help with CrowdStrike issue impacting Windows endpoints«. Comentarios de Hugo Vázquez Caramés en LinkedIn (CEO & Co-Founder at ExploitChance) sobre la información oficial de CrowdStrike. Análisis de los términos y condiciones de CrowdStrike en Twitter/X por Ivan Kwiatkowski (Lead cyber threat researcher at HarfangLab – The EDR for Next-Gen CyberSecurity Experts).