Azure AI Vision
Azure Computer Vision equipa a los desarrolladores con un servicio unificado para acceder a varias funcionalidades de visión artificial de última generación.
Azure AI Vision: comprensión de la información contenida en orígenes de datos visuales
Computer Vision es un área fundamental de la inteligencia artificial (IA), se centra en comprender la información contenida en orígenes de datos visuales, como imágenes y vídeos. Esta rama de la inteligencia artificial tiene como objetivo emular la percepción visual humana mediante algoritmos avanzados para reconocer el contenido y el contexto de las entradas ópticas.
Azure Computer Vision equipa a los desarrolladores con un servicio unificado para acceder a varias funcionalidades de visión artificial de última generación. Actualizado para aprovechar las mejoras significativas que ofrece el modelo base Florence de Microsoft, Vision Services mejora considerablemente la funcionalidad de análisis de imágenes y proporciona funcionalidades de personalización innovadoras.
Con el servicio Image Analysis 4.0 actualizado, los desarrolladores pueden usar las API de Azure Computer Vision para integrar de forma rápida y sencilla una eficaz funcionalidad de análisis de imágenes en las aplicaciones. Estas características incluyen la creación de subtítulos de imágenes y descripciones legibles para personas, la extracción y la lectura de texto, la detección de caras y la búsqueda de entradas visuales mediante consultas de lenguaje natural.
Vision Studio proporciona a los desarrolladores una herramienta basada en interfaz de usuario con poco código para probar las funcionalidades de Image Analysis 4.0. Los desarrolladores de aplicaciones que usan Vision Studio pueden crear y entrenar modelos personalizados de clasificación de imágenes y detección de objetos, incorporando potentes funcionalidades de visión en aplicaciones sin necesidad de una experiencia de aprendizaje automático.
¿Qué es el modelo base Florence de Microsoft?
Image Analysis 4.0 tiene la tecnología del modelo base Florence de Microsoft, entrenado en miles de millones de pares de imágenes de texto. Mediante el uso de representaciones universales de lenguaje visual en forma de datos con el par texto-imagen, el modelo Florence se puede adaptar fácilmente a diversas tareas de Computer Vision, como la clasificación, recuperación, detección de objetos e inserción de subtítulos. El modelo base Florence proporciona funcionalidades vanguardistas de visión por ordenador y supone un paso importante para ofrecer una funcionalidad de reconocimiento visual que va cambiar el panorama.
Florence mejora considerablemente las funcionalidades de Vision Image Analysis, entre las que se incluyen subtítulos de imágenes mejorados e innovadoras funcionalidades de personalización con pocos datos. El entrenamiento con pocos datos implica el uso de algoritmos de Computer Vision para realizar predicciones basadas en un número limitado de imágenes de ejemplo. El objetivo del entrenamiento con pocos datos es crear modelos capaces de reconocer similitudes y diferencias entre imágenes y «aprender» a asociar imágenes similares con las mismas etiquetas, de forma muy parecida a la que usan los seres humanos para aprender a reconocer objetos de una pequeña muestra de fotos.
Los conjuntos de datos de entrenamiento masivos son necesarios para crear modelos de Computer Vision desde cero. Las funcionalidades de visión de Microsoft reducen considerablemente la ingeniería necesaria para lograr modelos listos para la empresa. Antes del desarrollo del modelo base Florence, Custom Vision Service de Microsoft ha habilitado el entrenamiento de modelos mediante un mínimo de 15 imágenes. Ahora, con Florencia, los usuarios pueden entrenar modelos con un mínimo incluso menor de cuatro imágenes.
Los servicios mejorados de análisis de imágenes del modelo base Florence permiten a los desarrolladores crear aplicaciones de Computer Vision sólidas y listas para el mercado capaces de conectar sus datos a interacciones de lenguaje natural, desbloquear información eficaz a partir de su contenido de imagen y vídeo, y extraer información de las características visuales.
Análisis de imágenes con Azure Computer Vision Image Analysis 4.0
El servicio Azure Computer Vision Image Analysis 4.0 está diseñado para permitir la extracción de una gran variedad de elementos visuales a partir de imágenes, dibujos de más de 10 000 conceptos y objetos para detectar, clasificar, subtitular y generar información. Con tecnología del modelo base Florence de Microsoft, el servicio Image Analysis actualizado usa algoritmos de última generación para procesar imágenes e interpretar información visual. Por ejemplo, el servicio se puede usar para buscar todas las personas de una imagen, clasificar el contenido de las imágenes y describir una imagen con una frase en inglés completa.
Accesible a través del SDK de Vision y las API REST, Image Analysis 4.0 proporciona a los desarrolladores inteligencia artificial avanzada para analizar imágenes para extraer información sobre sus características visuales.
Descripción y subtitulado de imágenes
Se puede acceder a los subtítulos de imágenes a través de las características Caption y Dense Captions de Image Analysis 4.0. Ambas características usan los últimos modelos de inteligencia artificial más innovadores basados en Florence para analizar una imagen y comprender y generar una frase o texto en inglés legible que describa su contenido.

Caption genera una sola frase que describe la imagen, evaluando el contenido de la imagen de forma holística. Esta característica puede ser útil para actividades como la generación automática de texto de imagen alternativo.
Dense Captions proporciona información complementaria mediante la generación de frases descriptivas para objetos individuales dentro de la imagen. Estos subtítulos pueden ayudar a mejorar la comprensión de los elementos que componen la imagen. La respuesta de Dense Captions API incluye las coordenadas del rectángulo delimitador de las regiones de imagen descritas. Esta característica se puede usar para generar descripciones para diferentes partes de una imagen.
Uso de consultas de lenguaje natural para buscar fotos
La búsqueda de imágenes consiste en recorrer una colección de imágenes para encontrar las fotos más parecidas a una imagen o texto de consulta dados. Las técnicas de recuperación de imágenes han usado tradicionalmente características extraídas de las imágenes, como etiquetas de contenido, etiquetas y descriptores, para comparar imágenes y clasificarlas según su similitud.
La recuperación de imágenes de Image Analysis 4.0 se basa en la técnica más eficaz de vectorización. La vectorización convierte imágenes en coordenadas de un espacio vectorial multidimensional. La búsqueda por similitud vectorial convierte las consultas entrantes en vectores y empareja las imágenes en función de la proximidad semántica, lo que suele producir resultados de búsqueda mejores y más precisos.
La recuperación de imágenes permite a los desarrolladores crear la capacidad de buscar imágenes mediante consultas de lenguaje natural y obtener resultados basados en el contenido de la imagen en lugar de tener que confiar en etiquetas o etiquetas asignadas manualmente. Las API VectorizeImage y VectorizeText permiten la vectorización de imágenes y consultas de texto, lo que permite que las imágenes se emparejen mediante texto sin definir etiquetas de imagen u otros metadatos.
Generación de etiquetas basadas en el contenido de una imagen
El etiquetado de imágenes implica el uso de inteligencia artificial para identificar el contenido de una imagen, como objetos, acciones, seres vivos y paisajes. Image Analysis 4.0 puede generar etiquetas de contenido para miles de entidades reconocibles que aparecen en fotos.


El etiquetado de imágenes evalúa todo el contenido de la imagen, no solo el sujeto principal, como una persona en primer plano. Se generan etiquetas para el contenido de la imagen, como el entorno (interior o exterior), actividades, paisajes, puntos de referencia, colores, plantas, animales y otros objetos y acciones detectados.
Detección de objetos en imágenes
La detección de objetos es similar al etiquetado, pero la API devuelve una etiqueta además de las coordenadas del rectángulo que delimita cada objeto encontrado en la imagen. Por ejemplo, si una imagen contiene un perro, un gato y una persona, la operación de detección de objetos mostrará esos objetos con sus coordenadas en píxeles en la imagen. Puede usar esta funcionalidad para procesar las relaciones entre los objetos de una imagen. También permite determinar si existen varias instancias del mismo objeto en una imagen.
La función de detección de objetos solo busca objetos y seres vivos, que se pueden localizar con rectángulos delimitadores. Al mismo tiempo, la función de etiqueta también puede incluir términos contextuales como «interior», que se generalizan más en el contenido de la imagen.
Lectura de texto a partir de imágenes mediante el reconocimiento óptico de caracteres (OCR)
Image Analysis 4.0 permite a los desarrolladores extraer texto impreso o manuscrito de imágenes mediante una API sincrónica unificada mejorada para el rendimiento. Esta API simplifica la recuperación de resultados de reconocimiento óptico de caracteres (OCR) y de información adicional sobre la imagen, ya que permite recuperar la información mediante una sola llamada API y proporcionar compatibilidad con idiomas globales.

La nueva API unificada mejorada para el rendimiento de Image Analysis 4.0 proporciona una API rápida y sincrónica para escenarios que incluyen la ejecución de OCR en imágenes únicas con poco texto, lo que permite que OCR se inserte en experiencias de usuario casi en tiempo real para enriquecer la comprensión de contenidos y las acciones de seguimiento del usuario con tiempos rápidos de entrega.
Creación de imágenes en miniatura mediante Smart Cropping
Los desarrolladores de aplicaciones suelen usar representaciones de tamaño reducido de imágenes, a menudo denominadas miniaturas, para mostrar imágenes en interfaces de usuario de una manera más económica y fácil de diseñar. Image Analysis 4.0 usa Smart Cropping para generar imágenes en miniatura que incluyen las regiones más integrales de una imagen. Cuando se detectan personas dentro de la imagen, los recuadros delimitadores que las contienen tienen prioridad al crear miniaturas.
Smart Cropping API toma una o varias relaciones de aspecto y devuelve las coordenadas del rectángulo delimitador de las regiones identificadas. Los desarrolladores pueden configurar sus aplicaciones para usar los resultados para recortar y devolver la imagen mediante esas coordenadas.
Detección de personas que aparecen en las imágenes
La detección de personas en Image Analysis 4.0 representa una mejora en el modelo de detección de objetos subyacente, creado específicamente para detectar personas que aparecen en imágenes. Para cada persona detectada, se devuelven las coordenadas del rectángulo delimitador de la persona, junto con una puntuación de confianza.
La detección de personas no intenta distinguir caras dentro de la imagen ni predecir ni clasificar atributos faciales.
¿Qué es Vision Studio?
Vision Studio es la herramienta más reciente de Azure Computer Vision y proporciona una experiencia unificada del portal para explorar, crear e integrar la funcionalidad de Image Analysis 4.0 mediante un conjunto de componentes basados en la interfaz de usuario. La plataforma ofrece numerosas experiencias de demostración accesibles desde un navegador web. Permite a los desarrolladores explorar e interactuar con las funcionalidades de Vision existentes para comprender cómo funcionan operaciones específicas.
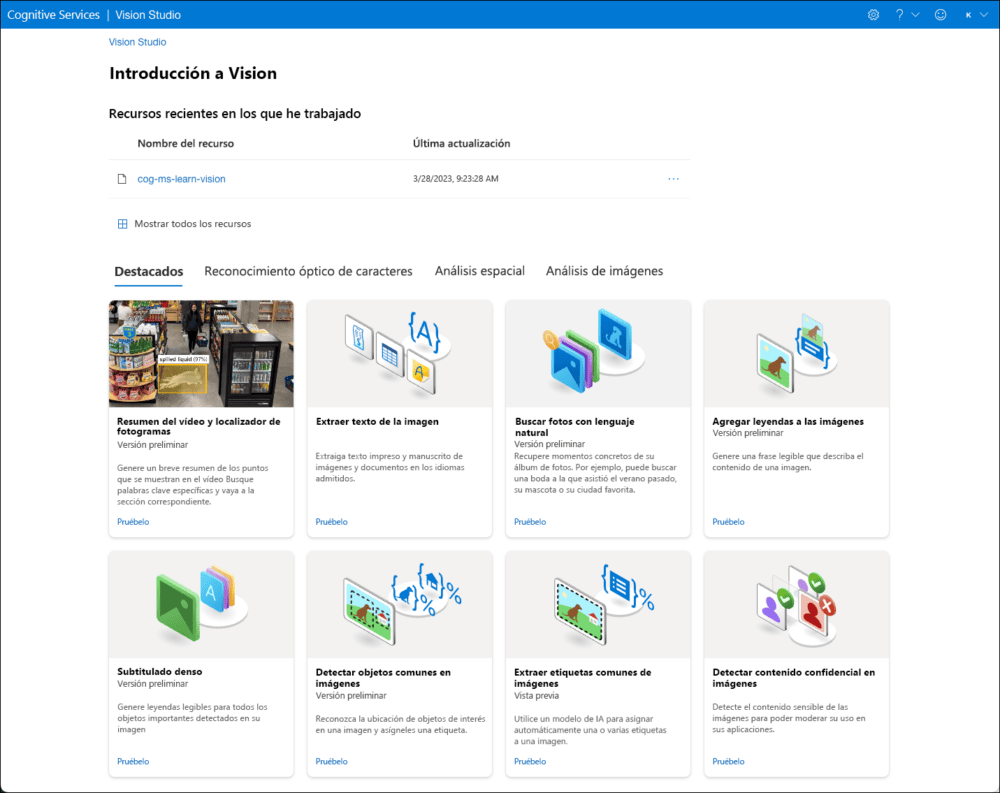
Con Studio se pueden usar todos los servicios y conocer lo que ofrecen sin necesidad de escribir ningún código. Para usar Vision Studio, necesitas una suscripción de Azure para la autenticación y un recurso de Cognitive Services para comenzar.
Esta información está basada la formación de Microsoft Learn sobre Azure AI Vision.