
Azure OpenAI ahora soporta fine-tuning de los modelos
Azure OpenAI acaba de recibir una emocionante actualización y es que desde ahora el fine-tuning de modelos de inteligencia artificial está disponible para nuevos modelos de inteligencia artificial: GPT-3.5 Turbo, Babbage-002 y Davinci-002.
Esta actualización allana el camino para que los desarrolladores adapten sus modelos favoritos de OpenAI con datos personales, y desplieguen sin problemas estos modelos personalizados, todo dentro de un servicio gestionado fácil de usar.
A tener en cuenta
🌞 Considera el fine-tuning, si tu objetivo es impartir nuevas habilidades al modelo para tareas distintas, navegar por escenarios complejos cargados de numerosos ejemplos o recortar la latencia incrustando indicaciones largas en el modelo, el ajuste fino podría ser tu billete de oro.
🚫 Por otro lado, si buscas resultados rápidos, necesitas datos actuales o especializados, o quieres un modelo bien fundamentado para evitar alucinaciones, la ingeniería de prompts y la Retrieval Augmented Generation (RAG) son probablemente una mejor opción.
¿Qué novedades hay en Azure OpenAI Service?
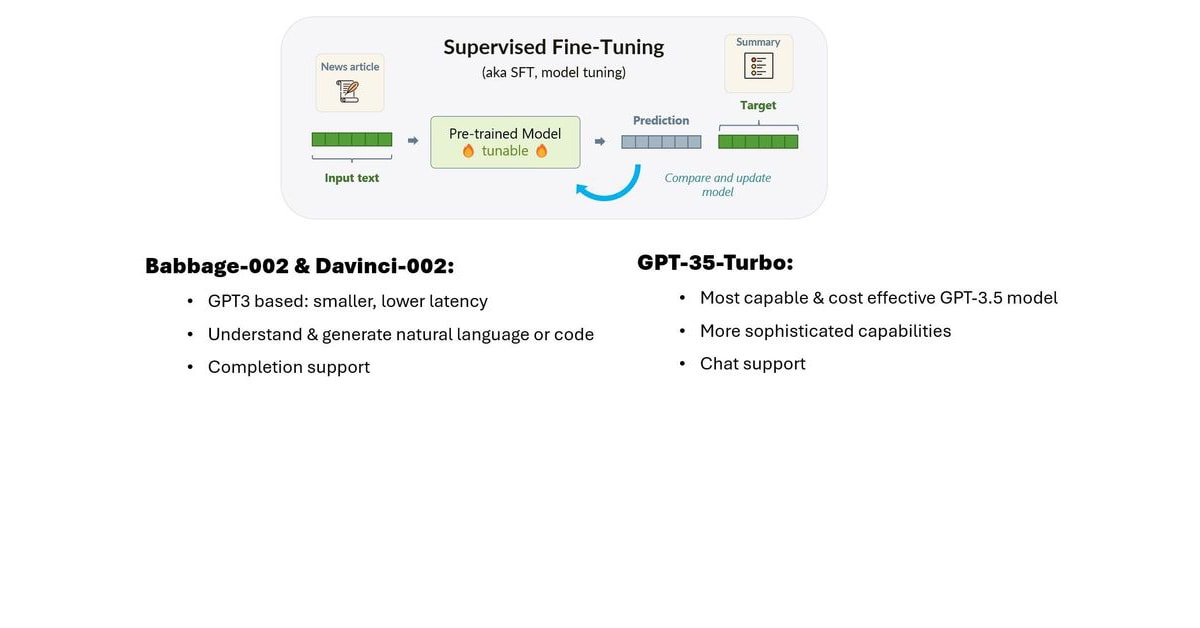
Hoy lanzamos dos nuevos modelos de inferencia base (Babbage-002 y Davinci-002) y capacidades de ajuste fino para tres modelos (Babbage-002, Davinci-002 y GPT-3.5-Turbo).
- Nuevos modelos: Babbage-002 y Davinci-002 son modelos base de GPT3, pensados para casos de uso de finalización. Pueden generar lenguaje natural o código, pero no están entrenados para seguir instrucciones. Babbage-002 sustituye a los modelos obsoletos Ada y Babbage, mientras que Davinci-002 sustituye a Curie y Davinci. Estos modelos son compatibles con la API de finalización («completion API«).
- Fine-tuning: Ahora podrá utilizar Azure OpenAI Service o Azure Machine Learning para ajustar Babbage/Davinci-002 y GPT-3.5-Turbo. Babbage-002 y Davinci-002 admiten la finalización («completion«), mientras que Turbo admite interacciones conversacionales. Podrás especificar tu modelo base, proporcionar tus datos, entrenar y desplegar, todo con unos pocos comandos.
Más información sobre el fine-tuning
El perfeccionamiento «fine-tuning» es uno de los métodos de que disponen los desarrolladores y científicos de datos que desean personalizar grandes modelos lingüísticos para tareas específicas. Mientras que enfoques como Retrieval Augmented Generation (RAG) y prompt engineering funcionan inyectando la información y las instrucciones adecuadas en su prompt, el fine-tuning funciona personalizando el propio modelo de lenguaje de gran tamaño.
Azure OpenAI Service y Azure Machine Learning ofrecen el fine-tuning supervisado, que le permite proporcionar datos personalizados (aviso/completado o chat conversacional, dependiendo del modelo) para enseñar nuevas habilidades al modelo base.
Piensa en el ajuste fino como una función de «modo experto»: muy potente, pero que requiere una base sólida construida sobre los fundamentos. El fine-tuning puede mejorar los buenos modelos, pero para tener éxito se necesita un caso de uso apropiado, datos de alta calidad y los modelos y avisos adecuados.
Qué significa el fine tuning para desarrolladores
Antes de empezar con el ajuste fino, le recomendamos que empiece con ingeniería de avisos o RAG (Retrieval Augmented Generation) para desarrollar una línea de base – es la forma más rápida de empezar, y se lo facilitamos con herramientas como Prompt Flow u On Your Data. Empezar con ingeniería de consultas y RAG proporcionará una línea de base con la que podrá comparar en escenarios en los que necesite ajustar un modelo. La mayoría de los modelos ajustados en producción incorporarán tanto la ingeniería rápida como el ajuste fino, por lo que no se desperdicia ningún esfuerzo.
¿Necesita ayuda para decidir cuándo (o si) debe realizar el ajuste fino? Algunas reglas básicas pueden servirle de guía.
No empieces con el fine-tuning si:
- Quieres un resultado sencillo y rápido: el fine-tuning va a requerir muchos datos y tiempo para entrenar y evaluar su nuevo modelo. Si no dispones de mucho tiempo, puedes llegar bastante lejos con la ingeniería de prompts.
- Necesitas datos actualizados o fuera del dominio: ¡ese es un caso de uso perfecto para RAG y la ingeniería de prompts!
- Deseas asegurarte de que tu modelo está bien fundamentado y evitar alucinaciones: ¡ésta es otra área en la que RAG brilla!
Considera usar el fine-tuning si:
- Quieres enseñar al modelo una nueva habilidad para que sea bueno en una tarea específica como clasificación, resumen, o responder siempre en un formato o tono específico. A veces se puede ajustar un modelo más pequeño para que realice una tarea específica igual de bien que un modelo más grande.
- Quieres mostrar al modelo cómo hacer algo con ejemplos, cuando es demasiado difícil de explicar en el prompt – o hay demasiados ejemplos para que quepan en la ventana de contexto. Se trata de escenarios con muchos casos extremos, como consultas en lenguaje natural o enseñar a un modelo a hablar con una voz o un tono específicos.
- Quieres reducir la latencia. Las peticiones largas pueden tardar más en procesarse, y el ajuste fino permite trasladar esas peticiones largas al propio modelo.
Primeros pasos con el fine-tuning en Azure
El fine-tuning con Azure Open AI Service te ofrece lo mejor de ambos mundos: la capacidad de personalizar los LLM avanzados de OpenAI, a la vez que se implementa en los servicios en la nube seguros y preparados para empresas de Azure. Uno de los riesgos del fine-tuning es introducir inadvertidamente datos dañinos en su modelo; la moderación de contenido de Microsoft te permite ajustar con los datos que necesitas, al tiempo que filtras cualquier respuesta dañina.
Microsoft ofrece una API súper sencilla para entrenar y desplegar tus modelos – o si te sientes más cómodo con una GUI, prueba Azure OpenAI Studio. Si estás migrando a Azure desde OpenAI, ¡las APIs de Microsoft son compatibles!
El fine-tuning consta de dos partes: el entrenamiento del modelo ajustado y el uso del modelo recién personalizado para la inferencia.
Entrenamiento: Especifica tu modelo base, tus datos de entrenamiento y validación, y establece cualquier hiperparámetro – ¡y ya estás listo! Puedes utilizar Azure OpenAI Studio para una interfaz gráfica de usuario sencilla, o los usuarios más avanzados pueden utilizar nuestras API REST o el OpenAI Python SDK.
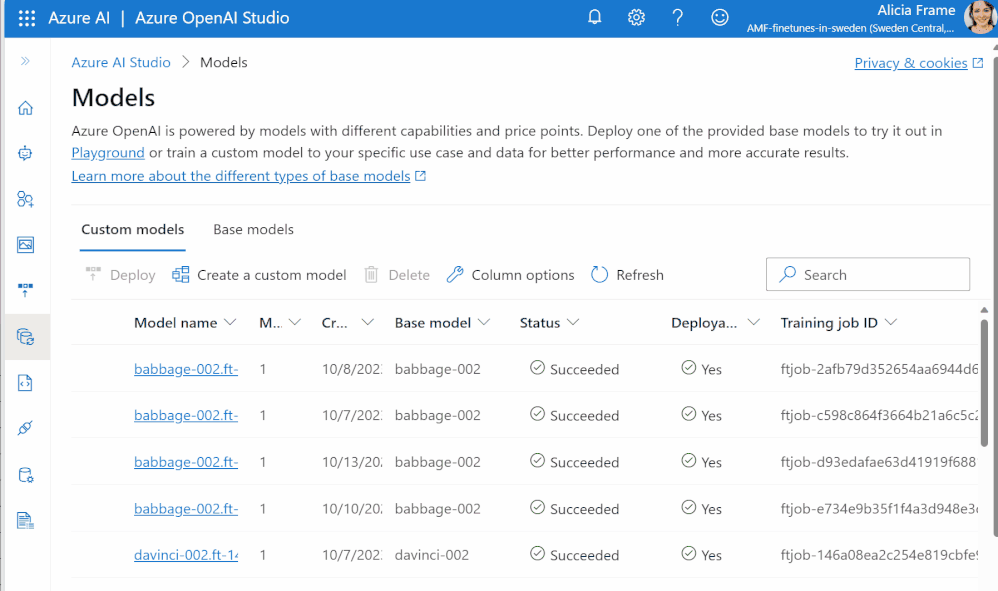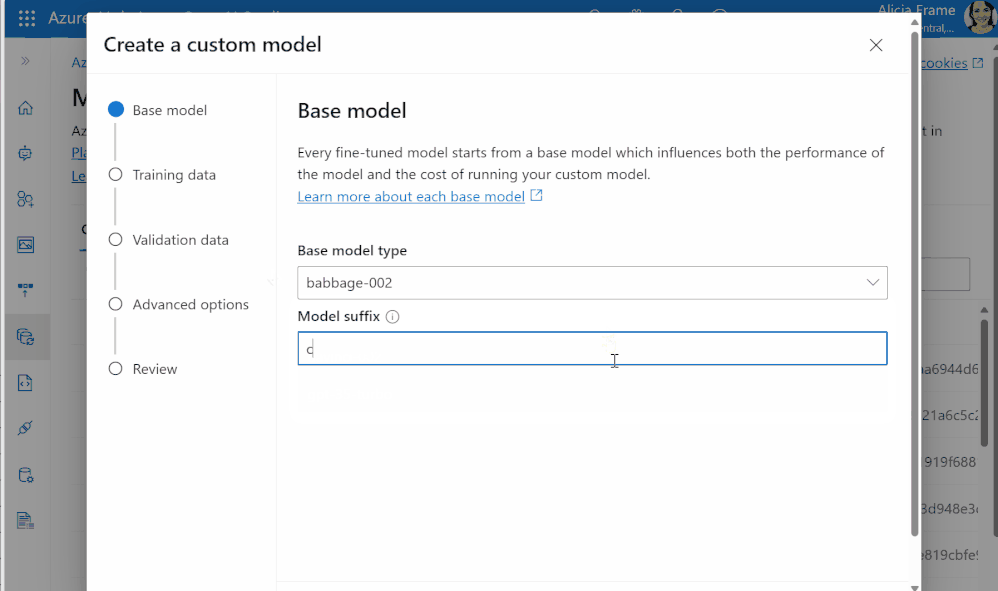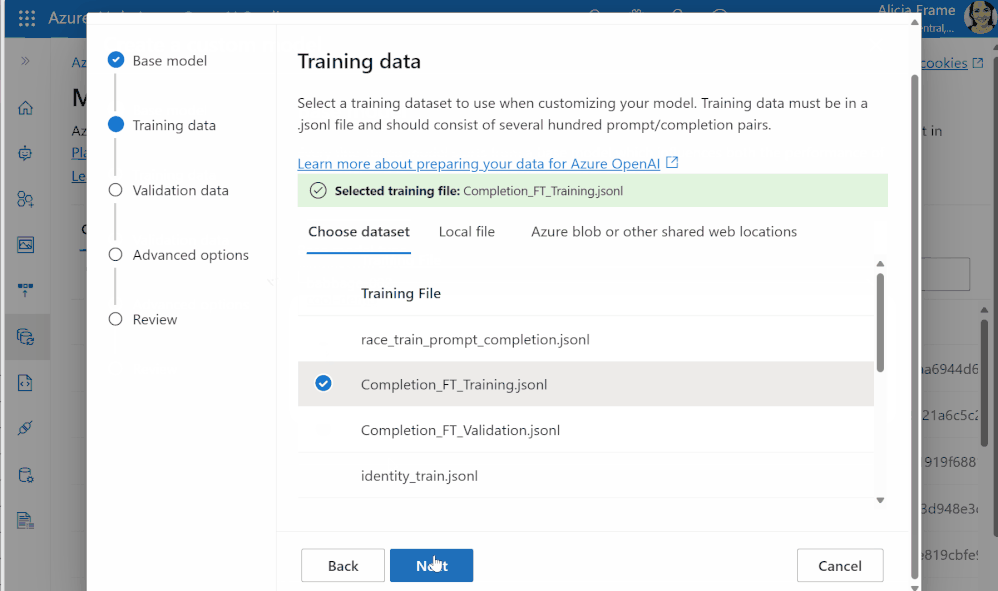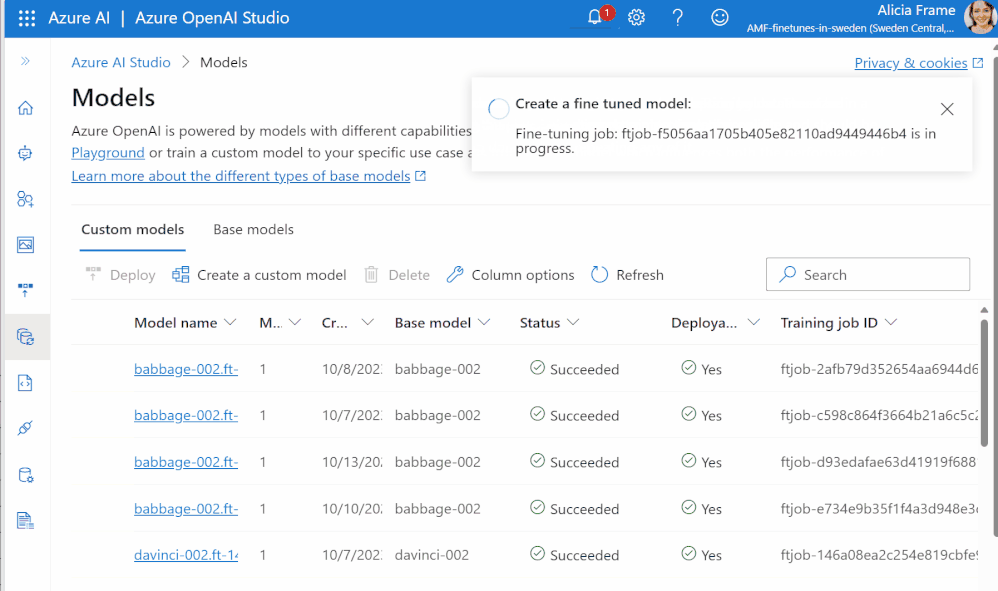
Cuando hayas terminado el fine tuning, tu trabajo completado devolverá métricas de evaluación como la pérdida de entrenamiento y validación.
Ofrecemos el fine-tuning como un servicio gestionado, por lo que no tienes que preocuparte de gestionar los recursos informáticos o la capacidad. Cuando envíes un trabajo, lo único que tendrás que pagar es el tiempo de entrenamiento activo, facturado en intervalos de 15 minutos, para las ejecuciones de ajuste con éxito. El precio depende del modelo base que hayas seleccionado.
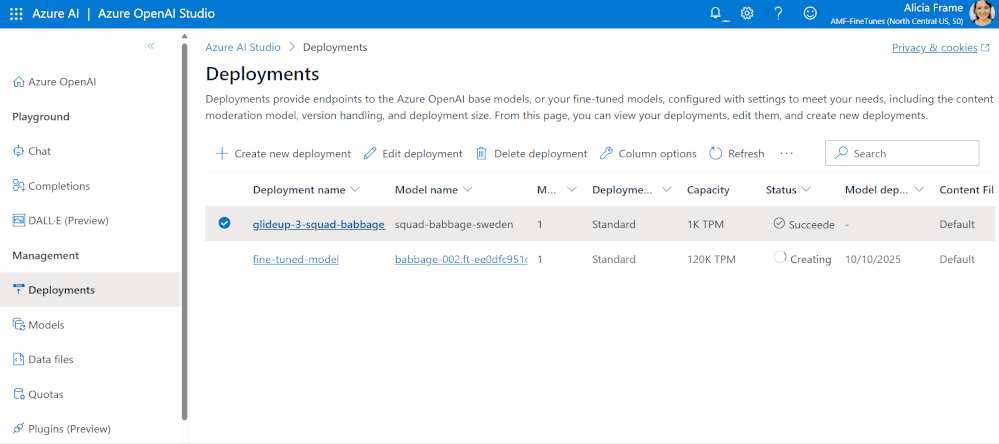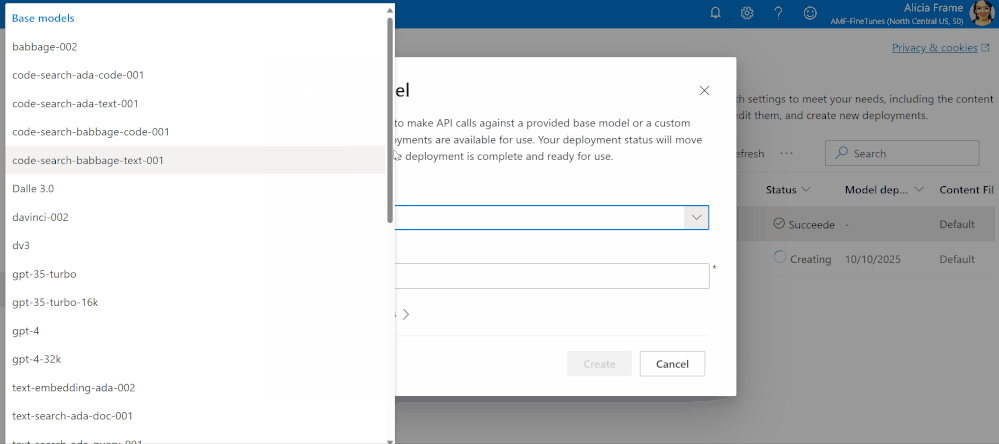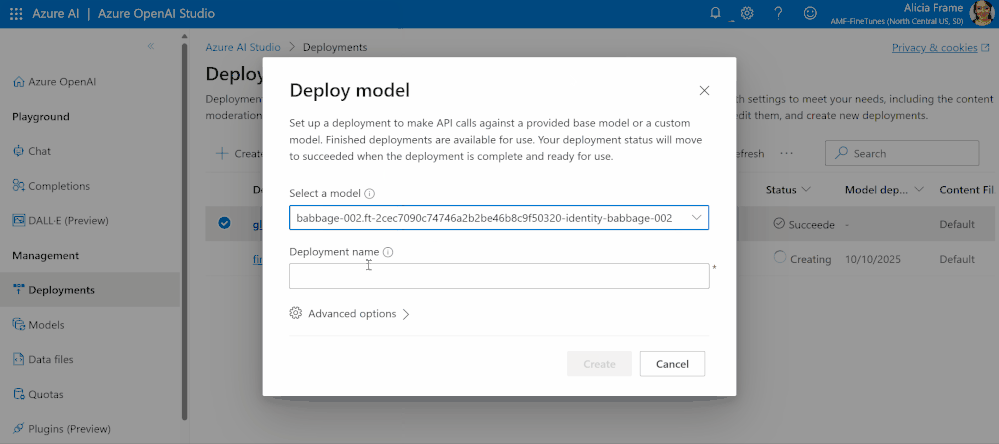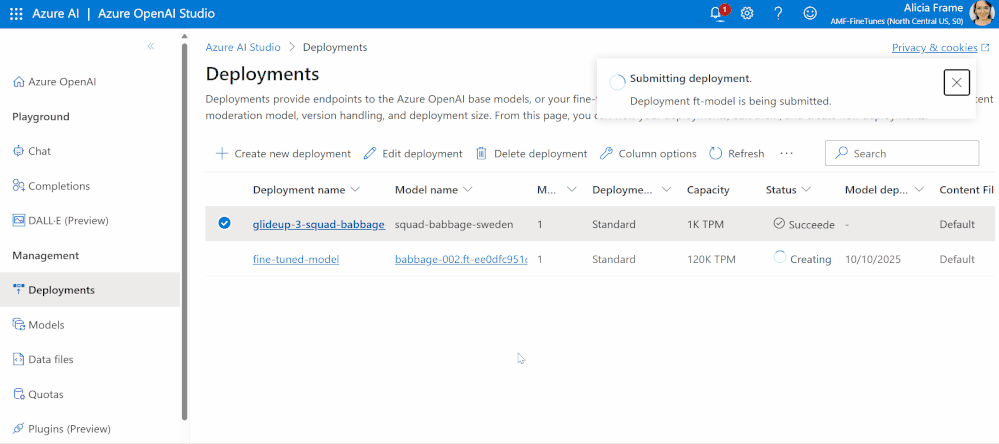
Inferencia en Azure OpenAI Service: Cuando el trabajo de entrenamiento sea un éxito, tu nuevo modelo estará disponible dentro de tu recurso. Cuando estés listo para empezar a usar tu modelo para inferir, ¡tu modelo personalizado puede ser desplegado como cualquier otro LLM de OpenAI!
Los modelos de fine-tuning están sujetos a un cargo de alojamiento por hora, así como a un precio basado en tokens para los datos de entrada y salida:
Si no necesitas utilizar tu modelo de inmediato, el almacenamiento de modelos entrenados es gratuito.
¡El fine-tuning también está disponible en Azure Machine Learning!
Si ya estás familiarizado con Azure Machine Learning Studio para desarrollar, monitorizar y desplegar modelos, ¡puedes integrar el fine-tuning en tus flujos de trabajo thereAML de modelos existentes! Los modelos OpenAI están disponibles en el catálogo de modelos, como parte de nuestra completa cartera de IA. Junto con los modelos de OpenAI, Azure Machine Learning también admite el ajuste fino de modelos OSS, como LLaMa.
¿Y esto que vale?
Los costes en el momento de la disponibilidad del fine-tuning (octubre de 2023) son estos:
- El entrenamiento se factura por intervalos de 15 minutos: Babbage-002 cuesta $34/hora, Davinci-002 cuesta $68/hora, y Turbo cuesta $102/hora.
- El modelo entrenado se despliega y se factura por hosting, input tokens y output tokens. Babbage-002 a $1.70/hora, Davinci-002 a $3.00/hora y GPT-35-Turbo a $7.00/hora.


