Ciencia de datos y analítica moderna con Microsoft Fabric
El potencial de la IA es ilimitado, con profundas implicaciones para sectores como la sanidad, las infraestructuras inteligentes, el entretenimiento, el comercio minorista, la banca, la logística, la fabricación y otros.
Oportunidades de datos en la era de la IA
Nunca se insistirá lo suficiente en la importancia de los datos en la actual transición hacia una era marcada por la IA. Los datos se crean y capturan en todas partes a partir de dispositivos grandes y pequeños, aplicaciones e interacciones.
Las organizaciones líderes aprovechan los datos para llevar a cabo transformaciones digitales y obtener una ventaja competitiva en sus respectivos sectores. El estado actual de la IA ha amplificado exponencialmente estas oportunidades. La capacidad de la IA para analizar e interpretar datos a una escala sin precedentes permite a las organizaciones obtener conocimientos más profundos, tomar decisiones más informadas y crear experiencias más personalizadas para los clientes.
Capacidades comerciales de la IA en la actualidad
La IA es un vasto campo con múltiples ramas, cada una de las cuales presenta un enfoque único de la interpretación de datos, los mecanismos de aprendizaje y los procesos de toma de decisiones. Entender estos diversos enfoques de la IA ayuda a comprender su complejidad y la multitud de formas en que se aplica. Al comprender estas diversas ramas, las organizaciones pueden entender cómo pueden aprovechar el panorama de la IA.
- Aprendizaje automático: El aprendizaje automático es un subconjunto esencial de la IA. Es la piedra angular de muchos sistemas de IA, ya que permite a los ordenadores aprender de los datos y hacer predicciones o deducciones precisas. El aprendizaje automático opera en un ámbito en el que se generan diariamente cantidades ingentes de datos a través de diversas fuentes, como mensajes de texto, correos electrónicos, publicaciones en redes sociales y numerosos sensores integrados en un entorno. Los científicos de datos emplean este extenso conjunto de datos para entrenar modelos de aprendizaje automático capaces de hacer predicciones basadas en patrones discernidos.
El aprendizaje automático emplea varias técnicas para analizar datos y predecir resultados. Estas técnicas incluyen- Aprendizaje supervisado («supervised learning«): Maneja conjuntos de datos con etiquetas o una estructura predefinida, donde los datos sirven de maestro para entrenar a la máquina, mejorando su capacidad de predicción.
- Aprendizaje no supervisado («unsupervised learning«): Procesa conjuntos de datos sin etiquetas ni estructura. Descubre patrones y relaciones ocultos agrupando datos similares en clusters.
- Aprendizaje por refuerzo («reinforcement learning«): Implica un programa informático que interactúa con su entorno para aprender comportamientos, con el proceso de aprendizaje basado en un sistema de recompensas y penalizaciones.
- Aprendizaje profundo («deep learning«): El aprendizaje profundo es una rama más avanzada del aprendizaje automático. Utiliza redes neuronales artificiales inspiradas en la estructura del cerebro humano. Estas redes plantean preguntas anidadas, cuyas respuestas conducen a preguntas relacionadas. El aprendizaje profundo requiere un amplio entrenamiento en grandes conjuntos de datos, lo que lo hace especialmente adecuado para aplicaciones como el reconocimiento de imágenes.
- IA generativa: la IA generativa utiliza redes neuronales para escudriñar datos, reconocer patrones y generar resultados novedosos como texto, imágenes o código. Microsoft utiliza la IA generativa en varias aplicaciones, como Azure OpenAI Service, GitHub Copilot y Bing Image Creator.
- ChatGPT: ChatGPT, construido por OpenAI, es un modelo refinado de la serie GPT-3.5. Emplea una arquitectura de red neuronal basada en transformadores. Entrenado en un amplio conjunto de datos de texto y perfeccionado mediante interacciones conversacionales, ChatGPT genera respuestas teniendo en cuenta el contexto de la conversación y analizando las entradas del usuario. ChatGPT está disponible en Azure OpenAI Service, donde los desarrolladores pueden integrar experiencias personalizadas basadas en IA directamente en sus propias aplicaciones, todo ello respaldado por las capacidades únicas de supercomputación y empresariales de Azure.
Cambiar la forma en que se utilizan los datos
Se prevé que la IA sea el amplificador definitivo, aumentando el trabajo humano al liberar tiempo para actividades de más alto nivel, como la resolución de problemas novedosos. Según el Equipo de Educación de Microsoft, la IA promete oportunidades significativas en la educación, permitiendo experiencias de aprendizaje personalizadas y democratizando el acceso a recursos educativos de alta calidad. A medida que aumenta la adopción de la tecnología de IA, es crucial garantizar que sus beneficios se compartan equitativamente entre la sociedad, las instituciones y las organizaciones.
Sin embargo, para apoyar estas experiencias de IA adaptadas a una organización específica, debe haber una afluencia continua de datos limpios procedentes de sistemas analíticos bien gestionados y estrechamente integrados. Lamentablemente, debido a la fragmentación de los datos y del panorama tecnológico de la IA, los sistemas analíticos de muchas organizaciones parecen un laberinto de servicios especializados y desconectados. Para hacer frente a estos paisajes de datos fragmentados y sistemas de análisis desconectados, la fusión de las capacidades de datos y la IA surge como una solución unificadora. Mediante la integración y gestión de datos con IA, las organizaciones tienen la oportunidad de transformar un complejo panorama de servicios especializados en una plataforma integrada y escalable para la creación de valor.
Al unificar estos servicios, las organizaciones pueden ofrecer mejor un flujo constante de datos limpios y bien gestionados, una base fundamental para respaldar la creación de aplicaciones de IA dentro de organizaciones específicas. Este fuerte acoplamiento entre la IA y los datos sirve de catalizador para la transformación.
Evolucionar la IA y el aprendizaje automático en la estrategia de datos
La integración de la actual generación de IA y aprendizaje automático en la estrategia de datos es un cambio transformador que resulta muy prometedor para organizaciones de diversos sectores. Estas tecnologías ofrecen un conjunto de capacidades que revolucionan la forma en que las organizaciones entienden y utilizan los datos, reconsiderando así las oportunidades y limitaciones de sus capacidades organizativas.
Estratégicamente, las organizaciones pueden incorporar la IA y el aprendizaje automático en tres grandes áreas: análisis, mejora de productos e investigación y desarrollo (I+D). El aprendizaje profundo, un componente crucial del aprendizaje automático
hace accesibles datos antes inaccesibles, extrayendo información valiosa de datos no estructurados como archivos de vídeo y audio. Esto amplía el alcance de la analítica, ofreciendo soluciones innovadoras a problemas complejos de la ciencia de datos y generando nuevas oportunidades de productos.
En el comercio electrónico, la IA y el aprendizaje automático han mejorado significativamente los sistemas de recomendación, haciendo que la experiencia de compra sea más personalizada y eficiente. Al ampliar los límites de las capacidades técnicas, estas tecnologías también influyen en la función de I+D, allanando el camino para descubrimientos pioneros. Por lo tanto, una integración estratégica de la IA y el aprendizaje automático en la estrategia de datos de una organización puede dar lugar a una toma de decisiones más perspicaz y a una innovación potencialmente disruptiva.
Aprovechar el potencial de la IA permite a las empresas y organizaciones:
- Equilibrio entre analítica, desarrollo de productos e I+D: Las empresas deben garantizar un enfoque equilibrado entre analítica, desarrollo de productos e I+D. Aunque las medidas de ahorro de costes pueden parecer atractivas inicialmente, la inversión en nuevas oportunidades de ingresos podría proporcionar importantes beneficios a largo plazo.
- Fomentar la experimentación en los proyectos de ciencia de datos: A diferencia de los proyectos tradicionales de ingeniería de software, los proyectos de ciencia de datos conllevan incertidumbres inherentes. Es esencial que las organizaciones fomenten una cultura que aliente la experimentación y perciba el fracaso como un camino hacia el éxito, no como un fin.
- Mantener una perspectiva pragmática: En medio del revuelo que rodea a la IA, es fundamental que las empresas mantengan los pies en la tierra. Deben evaluar críticamente las afirmaciones que se hacen sobre estas tecnologías y comprender su funcionamiento fundamental. La IA, aunque poderosa, es una herramienta que, cuando se utiliza eficazmente, puede ofrecer una visión sin precedentes, mejorar la toma de decisiones e impulsar el crecimiento empresarial.
La era de la IA trae consigo oportunidades y retos que alteran los paradigmas a partes iguales. Mediante la comprensión y el uso de estas tecnologías, las organizaciones pueden desbloquear un valor empresarial sin precedentes y asegurar su lugar en el panorama competitivo.
Proyectos de ciencia de datos en Microsoft Fabric
Los proyectos de ciencia de datos pueden ser complejos, especialmente cuando se trata de grandes volúmenes de datos. Sin embargo, con la estructura y las herramientas adecuadas, estos proyectos pueden gestionarse de forma eficaz y eficiente. Microsoft Fabric proporciona un amplio conjunto de recursos para facilitar el ciclo de vida de un proyecto de ciencia de datos.
El ciclo de vida de un proyecto de ciencia de datos puede dividirse en varias etapas clave:
- Entender el negocio: Un paso inicial crítico, esto implica definir el problema que el proyecto de ciencia de datos está tratando de resolver y alinearlo con los objetivos generales del negocio. El objetivo es garantizar que las metas del proyecto sean claras, mensurables y estén directamente relacionadas con los objetivos estratégicos de la organización.
- Adquirir y comprender los datos: Este paso consiste en recopilar los datos pertinentes y analizarlos para extraer información valiosa. Esta etapa puede resultar complicada debido al enorme volumen de datos y a la necesidad de identificar y extraer la información más relevante. Sin embargo, Fabric ofrece herramientas que facilitan la ingesta y exploración de datos, lo que facilita este proceso.
- Construir el modelo: La etapa de modelado implica el uso de los datos recopilados y comprendidos para construir modelos predictivos. Esto puede hacerse utilizando diversas metodologías, como el aprendizaje automático o la IA. Fabric ofrece una serie de herramientas y funciones para facilitar este proceso, incluido el uso de MLflow para el seguimiento de experimentos y el registro de modelos.
- Despliegue del modelo: Una vez construido el modelo, es necesario desplegarlo. Esto implica integrar el modelo en los sistemas y procesos existentes de la organización, asegurándose de que funciona correctamente y ofrece los resultados esperados. Fabric proporciona herramientas para apoyar este proceso, incluida la función PREDICT para generar predicciones por lotes.
- Gestionar el proyecto: Por último, la gestión del proyecto implica supervisar su progreso, realizar los ajustes necesarios y garantizar que se mantiene en el buen camino para alcanzar sus objetivos. Fabric proporciona una serie de recursos para apoyar la gestión de proyectos, incluida una representación visual del proceso de la ciencia de datos y la capacidad de rastrear experimentos y gestionar modelos.
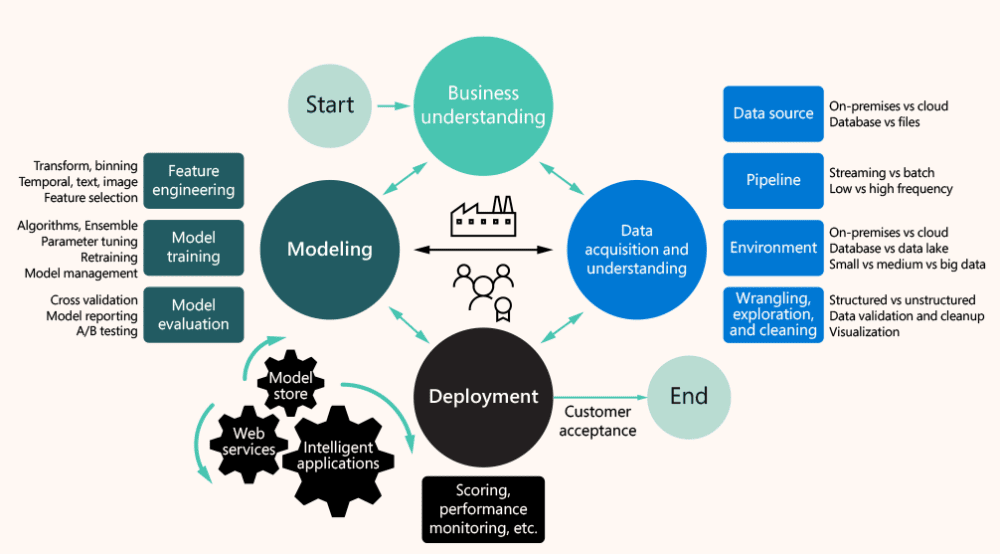
Cada una de estas etapas conlleva sus propias consideraciones, pero con el enfoque y el conjunto de herramientas adecuados, pueden abordarse con eficacia.
Superar los riesgos asociados a los proyectos de ciencia de datos
Navegar por el complejo panorama de un proyecto de ciencia de datos suele estar plagado de diversos riesgos y desafíos:
- Uno de los obstáculos más importantes es garantizar la calidad de los datos. Cuando los datos son inexactos o de mala calidad, pueden sesgar los resultados, lo que conduce a resultados ineficaces y potencialmente engañosos.
- La seguridad y la privacidad de los datos son otros aspectos críticos a tener en cuenta. Con regulaciones estrictas como el Reglamento General de Protección de Datos (GDPR), los datos deben manejarse de manera responsable para evitar repercusiones legales.
- Integrar las ideas y soluciones derivadas de los proyectos de ciencia de datos en los procesos empresariales existentes puede ser una tarea compleja y enfrentarse a la resistencia de varias partes interesadas.
Buenas prácticas para gestionar un proyecto de ciencia de datos
La gestión eficaz de un proyecto de ciencia de datos exige la adopción de varias buenas prácticas:
- Comenzar con objetivos claramente definidos que proporcionen una hoja de ruta para el proyecto.
- Asegúrar que los datos utilizados son de alta calidad y pertinentes para el problema en cuestión.
- Reunir un equipo cualificado y utilizar las herramientas adecuadas. Microsoft Fabric, con sus capacidades para simplificar la ingestión de datos, la exploración, el modelado, el despliegue y la gestión de proyectos, resulta inestimable en este sentido.
- Realizar revisiones periódicas del proyecto para ayudar a identificar posibles problemas desde el principio, lo que permitirá corregir el rumbo a tiempo.
- Mantener a las partes interesadas involucradas e informadas durante todo el proyecto para garantizar su aceptación y apoyo.
- Dar prioridad a la seguridad de los datos y al cumplimiento de la normativa de protección de datos para proteger el proyecto de posibles problemas legales.
El ciclo de vida de un proyecto de ciencia de datos puede ser complejo y difícil. Sin embargo, con las herramientas y los recursos adecuados, como los que proporciona Fabric, los científicos de datos pueden garantizar que sus proyectos ofrezcan información valiosa y contribuyan a los objetivos estratégicos de su organización.
Arquitectura de un proyecto de ciencia de datos en Microsoft Fabric
Los proyectos de ciencia de datos requieren una arquitectura bien pensada para gestionarlos y ejecutarlos con eficacia. Utilizando Microsoft Fabric, un proyecto de ciencia de datos puede estructurarse de forma que garantice un flujo de procesos sin fisuras, desde la ingestión de datos hasta la visualización y el análisis en tiempo real.
Fabric ofrece un marco integral para implementar proyectos de ciencia de datos. Esta arquitectura está construida para manejar escenarios de ciencia de datos de extremo a extremo que incluyen:
- Ingesta de datos de diversas fuentes
- Exploración y visualización de datos
- Limpieza de datos
- Entrenamiento y evaluación de modelos
- Puntuación por lotes
- Visualización de resultados de predicción
La arquitectura Fabric está diseñada para trabajar con diferentes componentes de un escenario de ciencia de datos, como fuentes de datos, modelos, almacenamiento y análisis. Fabric facilita la conexión a varios servicios de datos, plataformas en la nube y fuentes de datos locales para la ingestión de datos. La experiencia de la ciencia de datos en Fabric admite la limpieza, transformación, exploración y featurización de datos mediante experiencias integradas en herramientas basadas en Spark y Python.
Comprender los diferentes componentes de un escenario de ciencia de datos
La arquitectura de un proyecto de ciencia de datos con Microsoft Fabric implica varios componentes.
- Fuentes de datos: Fabric permite una conexión rápida y sencilla a los servicios de datos de Azure, otras plataformas en la nube y fuentes de datos locales para la ingesta de datos. Los científicos de datos pueden ingerir datos en cuadernos de Microsoft Fabric desde varias fuentes, incluyendo un lakehouse incorporado, almacenes de datos, conjuntos de datos de Power BI y fuentes de datos personalizadas compatibles con Apache Spark y Python.
- Exploración y preparación de datos: Fabric admite la limpieza, transformación, exploración y featurización de datos utilizando experiencias incorporadas en Spark y herramientas basadas en Python como Data Wrangler y la biblioteca SemPy.
- Modelos y experimentos: Fabric permite a los usuarios entrenar, evaluar y puntuar modelos de aprendizaje automático utilizando experimentos incorporados y elementos de modelo. Se integra perfectamente con MLflow para el seguimiento de experimentos y el registro y despliegue de modelos.
- Almacenamiento: Fabric utiliza Delta Lake como capa de almacenamiento estándar, lo que permite que todos los motores de Fabric interactúen con el mismo conjunto de datos almacenado en un lago. Admite datos estructurados y no estructurados en almacenamiento basado en archivos y en formato tabular.
- Análisis e información: Los datos de un lakehouse pueden ser consumidos por Power BI para informes y visualización. También se pueden visualizar en cuadernos Fabric utilizando las bibliotecas de visualización nativas de Spark o Python.
Ejemplos del mundo real y casos prácticos
Microsoft Fabric se utiliza en varios sectores para agilizar los proyectos de ciencia de datos. Por ejemplo, en los sectores de la sostenibilidad y la energía, Fabric ayuda a los proveedores de energías renovables a combinar datos en tiempo real de turbinas eólicas o paneles solares con datos de clientes, prediciendo así futuras demandas de energía. Permite a los proveedores mejorar la eficacia de las fuentes de energía en función de las tendencias de uso e identificar nuevos modelos de negocio mediante análisis basados en IA.
En el sector de los servicios financieros, proporciona una plataforma para combinar la cartera de clientes y los datos de mercado, reforzando la prevención de riesgos mediante una potencia informática y analítica escalable. En el sector público, Fabric permite a los gobiernos combinar la investigación y los datos en todo el sector de la sanidad pública, utilizando el aprendizaje automático y la IA para identificar los riesgos y las tendencias sanitarias. También ayuda a los gobiernos a anticiparse a la demanda de los clientes a escala local y global, garantizando que el producto adecuado llegue al cliente adecuado en el momento adecuado.
La arquitectura de un proyecto de ciencia de datos que utiliza Fabric proporciona un marco sólido para gestionar escenarios complejos de ciencia de datos, ayudando a las organizaciones a desbloquear el potencial de sus datos e impulsar los conocimientos empresariales.
Copilot en Microsoft Fabric
Elegir la tecnología adecuada para la ciencia de datos puede ser un rompecabezas complejo con una abrumadora mezcla de herramientas. Microsoft Fabric simplifica este proceso actuando como un director maestro, orquestando varias herramientas de datos para crear una sinfonía armoniosa de análisis de datos. He aquí cómo Fabric agiliza los proyectos de ciencia de datos:
- Plataforma unificada: Al integrar Azure Data Factory, Azure Synapse Analytics y Power BI, Fabric crea una plataforma única que optimiza la utilización de los datos para los profesionales.
- OneLake: OneLake, una innovación clave, actúa como una vasta biblioteca para el almacenamiento de datos, simplificando el intercambio de datos y la colaboración en toda la organización.
- Modo Direct Lake: Una función innovadora que permite acceder a los datos a alta velocidad directamente desde OneLake, mejorando el rendimiento y la eficiencia.
- Formatos de datos abiertos: Fabric adopta formatos de datos abiertos como Delta Lake y Parquet como sus formatos de almacenamiento nativos, aliviando las preocupaciones de dependencia de proveedores y reduciendo las necesidades de replicación de datos.
- Colaboración: Fabric facilita el trabajo en equipo con la integración de Git para conjuntos de datos e informes de Power BI, lo que permite un seguimiento sencillo de los cambios, la fusión de actualizaciones y la reversión a versiones anteriores.
- Modelo de capacidad unificado: Este modelo simplifica la compra y gestión de recursos proporcionando un único pool de potencia computacional para todas las cargas de trabajo de Fabric, reduciendo así costes y complejidades.
Copilot en Microsoft Fabric ofrece funciones avanzadas de IA generativa que permiten a los profesionales de datos interactuar con la plataforma de formas muy productivas. Por ejemplo, los usuarios pueden simplemente describir los elementos visuales y las perspectivas que buscan, y Copilot analizará y extraerá los datos correctos en un informe. Además, permite adaptar rápidamente los informes, generar y editar código programático DAX de Power BI, crear resúmenes narrativos y formular preguntas sobre los datos, todo ello en un lenguaje conversacional. Copilot in Fabric potencia la productividad y la generación de valor de los usuarios finales, incluso para aquellos sin formación técnica.
Encuentre más valor en tus datos
Los datos alimentan la capacidad de la IA para aprender, adaptarse y ofrecer resultados precisos. Microsoft Fabric es una solución innovadora que reconoce la base subyacente sobre la que la IA construye sus capacidades de comprensión y toma de decisiones. Fabric transforma la potencia bruta de los datos en una fuerza que impulsa la evolución de la IA, integrando a la perfección las estructuras de datos modernas y la ciencia de datos en una base SaaS compartida. Al proporcionar un lago de datos unificado y una administración centralizada, Fabric aborda directamente los retos imperantes en la gestión y el análisis de datos.
Además, Fabric desempeña un papel crucial en los proyectos de ciencia de datos. Su sólida arquitectura admite todas las fases de la analítica, desde la ingestión y el procesamiento de datos hasta la visualización y la analítica en tiempo real. Los científicos de datos pueden gestionar proyectos complejos de forma eficaz y eficiente con Fabric, obteniendo información valiosa que impulsa la toma de decisiones estratégicas.
La integración de Copilot en Microsoft Fabric hace que la plataforma sea aún más fácil de usar. Permite a los usuarios generar código, construir modelos de aprendizaje automático y crear canalizaciones de datos utilizando un lenguaje sencillo y cotidiano. Esto reduce significativamente la curva de aprendizaje para la adopción de nuevas tecnologías, haciendo que la ciencia de datos avanzada sea accesible a una amplia gama de usuarios.
Microsoft Fabric se erige como un pilar para el futuro de la gestión y el análisis de datos impulsado por la IA. Está revolucionando las empresas de diversos sectores, poniendo la ciencia de datos avanzada al alcance de todos y contribuyendo significativamente al éxito sostenido de la IA.
Este post está basado en la publicación The essential guide to Microsoft Fabric for data leaders.