Optimiza tus prompts en OpenAI o1 con estos consejos
Los mejores prompts para el nuevo ChatGPT o1 son completamente diferentes por la cadena de pensamiento en la que se basa.
Los modelos de la serie o1 de OpenAI son nuevos modelos de lenguaje de gran tamaño entrenados con aprendizaje por refuerzo para realizar razonamientos complejos. Los modelos o1 piensan antes de responder y pueden producir una larga cadena interna de pensamientos antes de responder al usuario. Los modelos o1 destacan en el razonamiento científico, situándose en el percentil 89 en preguntas de programación competitivas (Codeforces), entre los 500 mejores estudiantes de EE.UU. en una prueba clasificatoria para la Olimpiada Matemática de EE.UU. (AIME) y superando la precisión de nivel de doctorado humano en una prueba comparativa de problemas de física, biología y química (GPQA).
Hay dos modelos de razonamiento disponibles en la API:
- o1-preview: una versión preliminar (a principio de septiembre de 2024) del modelo o1, diseñado para razonar sobre problemas difíciles utilizando un amplio conocimiento general sobre el mundo.
- o1-mini: una versión más rápida y barata de o1, especialmente adecuada para tareas de codificación, matemáticas y ciencias en las que no se requiere un amplio conocimiento general.
Los modelos o1 ofrecen avances significativos en el razonamiento, pero no están pensados para sustituir a GPT-4o en todos los casos de uso.
Los modelos GPT-4o y GPT-4o mini seguirán siendo la mejor elección para aplicaciones que requieran entradas de imágenes, llamadas a funciones o tiempos de respuesta rápidos y constantes.
Sin embargo, si tu objetivo es desarrollar aplicaciones que exijan un razonamiento profundo y puedan acomodarse a tiempos de respuesta más largos, los modelos o1 podrían ser una opción excelente.
Cómo funciona el razonamiento
Los modelos o1 introducen fichas de razonamiento. Los modelos utilizan estas fichas de razonamiento para «pensar», desglosando su comprensión de la pregunta y considerando múltiples enfoques para generar una respuesta. Después de generar fichas de razonamiento, el modelo produce una respuesta como fichas de finalización visibles, y descarta las fichas de razonamiento de su contexto.
Este es un ejemplo de conversación en varios pasos entre un usuario y un asistente. Los tokens de entrada y salida de cada paso se mantienen, mientras que los tokens de razonamiento se descartan.
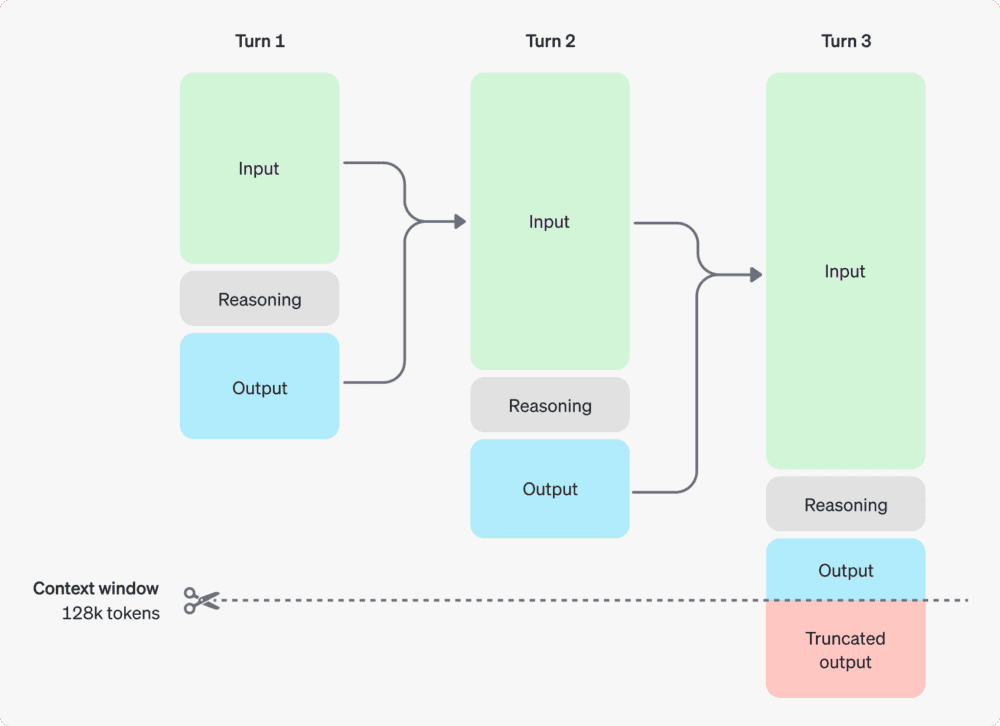
Gestión de la ventana contextual
Los modelos o1-preview y o1-mini ofrecen una ventana de contexto de 128.000 tokens. Cada finalización tiene un límite superior en el número máximo de tokens de salida, que incluye tanto los tokens de razonamiento invisibles como los tokens de finalización visibles. Los límites máximos de tokens de salida son:
- o1-preview: Hasta 32.768 tokens
- o1-mini: hasta 65.536 tokens
Es importante asegurarse de que hay suficiente espacio en la ventana de contexto para los tokens. Dependiendo de la complejidad del problema, los modelos pueden generar desde unos cientos hasta decenas de miles de fichas de razonamiento.
Consejos para crear prompts para o1
Estos modelos funcionan mejor con instrucciones directas. Algunas técnicas de ingeniería de prompts, como las indicaciones de pocos disparos o las instrucciones al modelo para que «piense paso a paso», pueden no mejorar el rendimiento y, en ocasiones, pueden entorpecerlo. He aquí algunas de las mejores prácticas:
- Las instrucciones deben ser sencillas y directas: los modelos son excelentes comprendiendo y respondiendo a instrucciones breves y claras, sin necesidad de una explicación exhaustiva.
- Evita las instrucciones en cadena: Dado que estos modelos razonan internamente, no es necesario pedirles que «piensen paso a paso» o «expliquen su razonamiento».
- Utiliza delimitadores para mayor claridad: Utilice delimitadores como comillas triples, etiquetas XML o títulos de sección para indicar claramente las distintas partes de la entrada y ayudar al modelo a interpretar adecuadamente las diferentes secciones.
- Limita el contexto adicional en la generación aumentada por recuperación (RAG): Cuando proporciones contexto o documentos adicionales, incluye sólo la información más relevante para evitar que el modelo complique en exceso su respuesta.
Información basada en la guía de OpenAI: «Reasoning models«.