

Janus-Pro-7B: Genera imágenes con DeepSeek (open-source)
DeepSeek acaba de lanzar otro modelo de IA de código abierto: Janus-Pro-7B que es multimodal y permite crear imágenes.
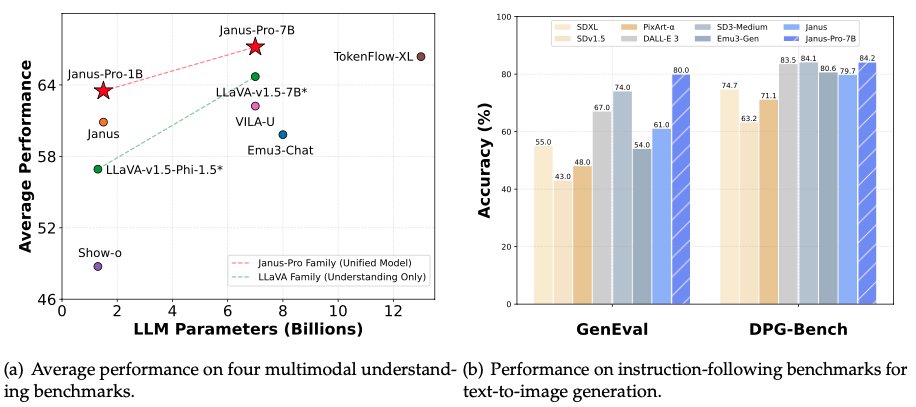
Es multimodal (puede generar imágenes) y supera a DALL-E 3 y Stable Diffusion de OpenAI en las pruebas GenEval y DPG-Bench.

Introducción a Janus-Pro
Janus-Pro es un nuevo marco autorregresivo que unifica la comprensión y la generación multimodales. Aborda las limitaciones de los enfoques anteriores desacoplando la codificación visual en vías separadas, sin dejar de utilizar una arquitectura de transformador única y unificada para el procesamiento. La disociación no sólo alivia el conflicto entre las funciones del codificador visual en la comprensión y la generación, sino que también mejora la flexibilidad del marco. Janus-Pro supera el modelo unificado anterior e iguala o supera el rendimiento de los modelos de tareas específicas. La simplicidad, alta flexibilidad y eficacia de Janus-Pro lo convierten en un firme candidato para la próxima generación de modelos multimodales unificados.
Resumen del modelo
Janus-Pro es un MLLM unificado de comprensión y generación, que desacopla la codificación visual para la comprensión y generación multimodal. Janus-Pro se basa en DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base.
Para la comprensión multimodal, utiliza el SigLIP-L como codificador de visión, que admite la entrada de imágenes de 384 x 384. Para la generación de imágenes, Janus-Pro utiliza el tokenizer de LlamaGen con una tasa de reducción de muestra de 16.
Información basada en la publicación de Hugging Face Janus Pro 7B, el repositorio de GitHub de Janus, la información de Hugging Face acerca de ViT-L-16-SigLIP-384 y el repositorio de GitHub de LlamaGen.


