DeepSeek R1: Razonamiento avanzado open-source
Si hace unas semanas os hablaba de DeepSeek v3 y la revolución que representaba, ahora llega DeepSeek R1 que razona.
DeepSeek ha presentado su primera generación de modelos DeepSeek-R1 y DeepSeek-R1-Zero, diseñados para abordar tareas de razonamiento complejas.
DeepSeek-R1-Zero se entrena únicamente mediante aprendizaje por refuerzo (RL1) a gran escala, sin depender del ajuste fino supervisado (SFT2) como paso previo. Según DeepSeek, este enfoque ha propiciado la aparición natural de «numerosos comportamientos de razonamiento potentes e interesantes», como la autoverificación, la reflexión y la generación de extensas cadenas de pensamiento (CoT3).
«En particular, [DeepSeek-R1-Zero] es la primera investigación abierta que valida que las capacidades de razonamiento de los LLM pueden incentivarse puramente mediante RL, sin necesidad de SFT», explicaron los investigadores de DeepSeek. Este hito no sólo subraya los fundamentos innovadores del modelo, sino que también allana el camino para los avances centrados en la RL en la IA de razonamiento».
Sin embargo, las capacidades de DeepSeek-R1-Zero tienen ciertas limitaciones. Entre los principales problemas se encuentran «la repetición interminable, la escasa legibilidad y la mezcla de lenguajes», que podrían plantear importantes obstáculos en las aplicaciones del mundo real. Para subsanar estas deficiencias, DeepSeek desarrolló su modelo estrella: DeepSeek-R1.
Presentación de DeepSeek-R1
DeepSeek-R1 se basa en su predecesor mediante la incorporación de datos de arranque en frío antes del entrenamiento de RL. Este paso adicional de preentrenamiento mejora las capacidades de razonamiento del modelo y resuelve muchas de las limitaciones observadas en DeepSeek-R1-Zero.
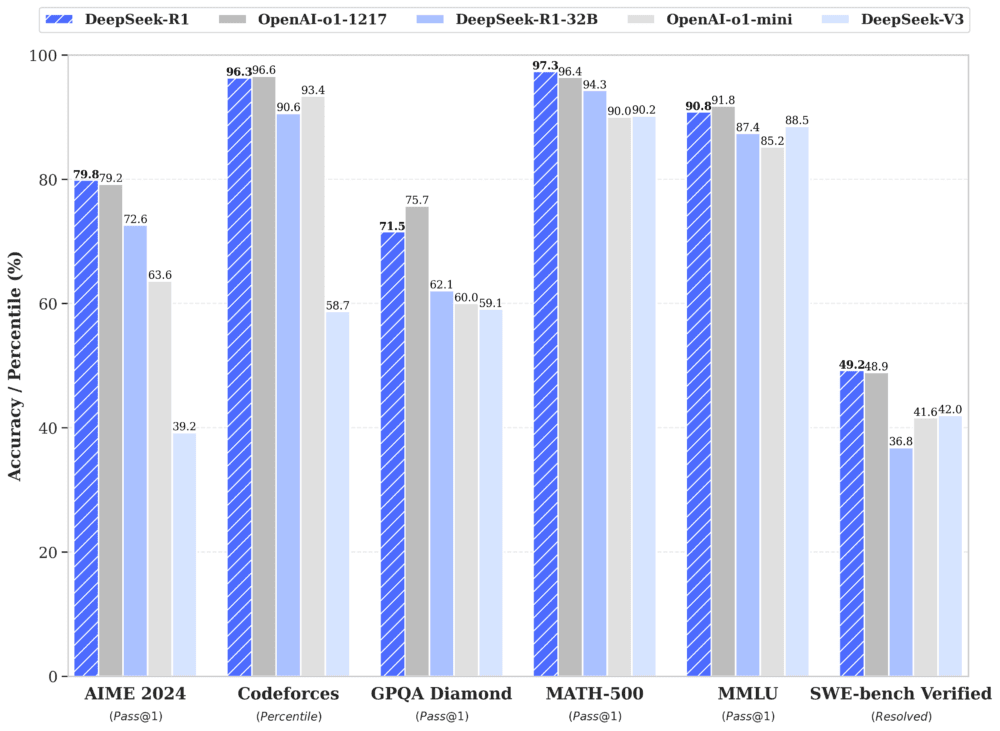
En particular, DeepSeek-R1 alcanza un rendimiento comparable al del sistema o1 de OpenAI en tareas matemáticas, de codificación y de razonamiento general, lo que lo consolida como uno de los principales competidores.
DeepSeek ha decidido publicar en código abierto DeepSeek-R1-Zero y DeepSeek-R1 junto con seis modelos más pequeños. Entre ellos, DeepSeek-R1-Distill-Qwen-32B ha demostrado unos resultados excepcionales, superando incluso a o1-mini de OpenAI en múltiples pruebas comparativas.
- MATH-500 (Aprobado@1): DeepSeek-R1 alcanzó un 97,3%, eclipsando a OpenAI (96,4%) y a otros competidores clave.
- LiveCodeBench (Pass@1-COT): La versión destilada DeepSeek-R1-Distill-Qwen-32B obtuvo un 57,2%, un rendimiento sobresaliente entre los modelos más pequeños.
- AIME 2024 (Pass@1): DeepSeek-R1 alcanzó un 79,8%, estableciendo un impresionante estándar en la resolución de problemas matemáticos.
Un proceso que beneficia a toda la industria
DeepSeek ha compartido información sobre su riguroso proceso de desarrollo de modelos de razonamiento, que integra una combinación de perfeccionamiento supervisado y aprendizaje por refuerzo.
Según la empresa, el proceso incluye dos fases de SFT para establecer las capacidades básicas de razonamiento y no razonamiento, así como dos fases de RL adaptadas para descubrir patrones de razonamiento avanzados y alinear estas capacidades con las preferencias humanas.
«Creemos que el proceso beneficiará a la industria al crear mejores modelos», señala DeepSeek, aludiendo al potencial de su metodología para inspirar futuros avances en el sector de la IA.
Un logro destacado de su enfoque centrado en RL es la capacidad de DeepSeek-R1-Zero para ejecutar intrincados patrones de razonamiento sin instrucción humana previa, una primicia en la comunidad de investigación de IA de código abierto.
Importancia de la destilación
Los investigadores de DeepSeek también destacaron la importancia de la destilación: el proceso de transferir las capacidades de razonamiento de modelos más grandes a otros más pequeños y eficientes, una estrategia que ha permitido mejorar el rendimiento incluso en configuraciones más pequeñas.
Las iteraciones destiladas más pequeñas de DeepSeek-R1 -como las versiones de 1,5B, 7B y 14B- fueron capaces de mantenerse en aplicaciones nicho. Los modelos destilados pueden superar los resultados obtenidos mediante el entrenamiento RL en modelos de tamaños comparables.
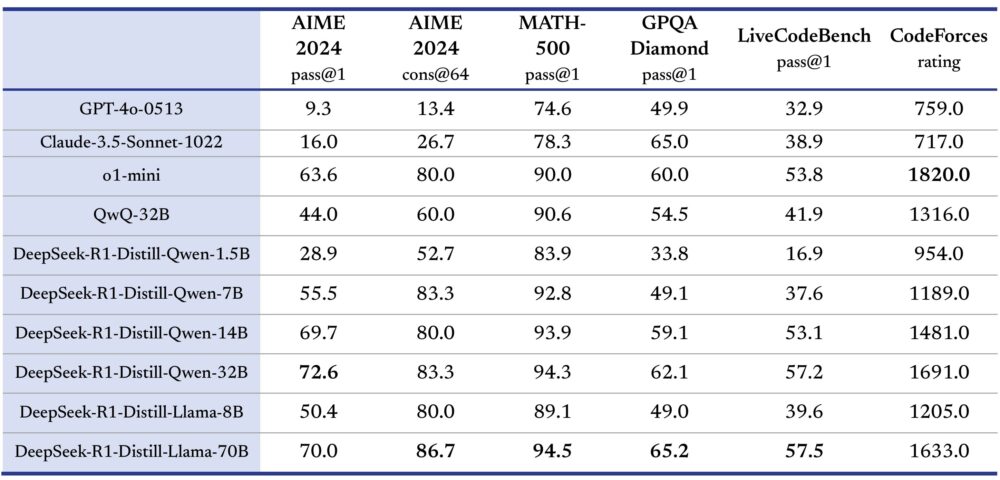
Para los investigadores, estos modelos destilados están disponibles en configuraciones que van de 1.500 millones a 70.000 millones de parámetros, compatibles con las arquitecturas Qwen2.5 y Llama3. Esta flexibilidad permite un uso versátil en una amplia gama de tareas, desde la codificación hasta la comprensión del lenguaje natural.
DeepSeek ha adoptado la Licencia MIT para su repositorio y pesos, ampliando los permisos para su uso comercial y modificaciones posteriores. Se permiten los trabajos derivados, como el uso de DeepSeek-R1 para entrenar otros modelos lingüísticos de gran tamaño (LLM). Sin embargo, los usuarios de modelos destilados específicos deben garantizar el cumplimiento de las licencias de los modelos base originales, como las licencias Apache 2.0 y Llama3.
¿Dónde están los puntos débiles de DeepSeek?
- En llamadas a funciones, interacciones en varios turnos, roles complejos y generación de outputs en JSON.
- En el idioma usado, está optimizado para ser usado en inglés y chino.
- En los prompts, recomiendan usar Zero-Shot Prompting para obtener resultados óptimos.
- Esto solo si no se usa el modelo en local y desde los servidores de DeepSeek: En el almacenamiento de información fuera de la UE, ya que toda la información se almacena en China.
Información basada en la publicación en X/Twitter de DeepSeek («DeepSeek-R1 is here!«) y las publicaciones en Notion «Deepseek-v3 101» y «Deepseek R1 for Everyone«. Y los puntos débiles extraídos de DeepSeek_R1.pdf en GitHub.