Estrategias de optimización de Inteligencia Artificial con RAG
Hoy comparto unas cuantas estrategias de optimización de los modelos inteligencia artificial generativa enriqueciéndolos con un mecanismo de recuperación de información, que mejorara la calidad y la precisión de las respuestas.
¿Qué es la generación mejorada por recuperación (RAG)?
La generación mejorada por recuperación (RAG · Retrieval-Augmented Generation) es el proceso de optimización de la salida de un modelo lingüístico de gran tamaño, de modo que haga referencia a una base de conocimientos autorizada fuera de los orígenes de datos de entrenamiento antes de generar una respuesta.
Los modelos de lenguaje de gran tamaño (LLM) se entrenan con grandes volúmenes de datos y usan miles de millones de parámetros para generar resultados originales en tareas como responder preguntas, traducir idiomas y completar frases.
RAG extiende las ya poderosas capacidades de los LLM a dominios específicos o a la base de conocimientos interna de una organización, todo ello sin la necesidad de volver a entrenar el modelo.
¿Cómo funciona RAG?
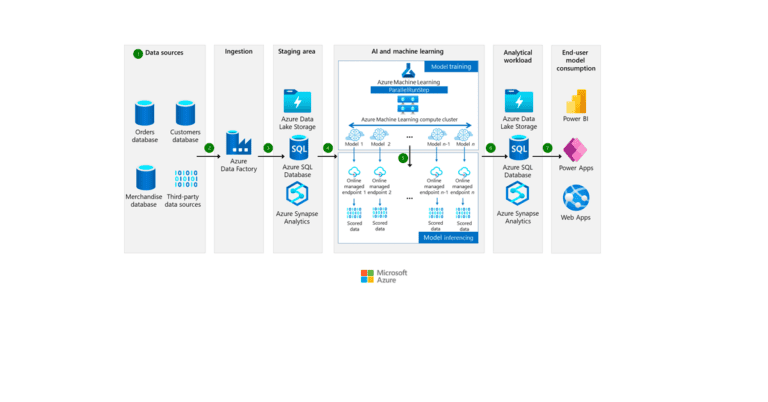
RAG combina la generación de texto con la capacidad de buscar información relevante para mejorar la precisión y la relevancia de las respuestas generadas. En un modelo RAG:
- Recuperación: El modelo primero busca en una base de datos o conjunto de documentos para encontrar información relevante. Esto se hace generalmente mediante un modelo de recuperación de documentos que puede buscar a través de una gran cantidad de texto para encontrar los fragmentos más relevantes para una consulta dada.
- Generación: Luego, el modelo de generación de texto (como por ejemplo GPT-3) utiliza esta información recuperada para generar una respuesta. Esto permite que el modelo produzca respuestas que no solo se basan en su entrenamiento previo, sino también en información específica y actualizada recuperada de su base de datos.
Este proceso permite que RAG genere respuestas más informadas y específicas a preguntas que podrían requerir conocimiento actualizado o detallado, más allá de lo que se incluyó en su entrenamiento inicial.
Es una forma de combinar la generación de lenguaje basada en modelos de inteligencia artificial con la búsqueda de información en tiempo real, mejorando significativamente la relevancia y precisión de las respuestas en comparación con los modelos que solo dependen de la generación basada en el entrenamiento previo.
Estrategias para optimizar las implementaciones RAG
Estrategias básicas de optimización de implementaciones RAG
- Utiliza instrucciones efectivas. Hablaba de esto aquí: «No seas amable con tu IA, se directo«.
- Comprender los retos: no sobreoptimizar y, en primer lugar, identificar realmente los problemas comunes con la recuperación, el aumento y la generación. siempre conviene empezar por lo sencillo.
- Elije el tamaño de fragmento adecuado: determina el tamaño de fragmento óptimo para tus datos con el fin de garantizar un procesamiento y una recuperación eficientes. los solapamientos de trozos no siempre funcionan; utilice trozos más pequeños…
- Utiliza resúmenes para los fragmentos de datos: aplica técnicas de resumen a los fragmentos de datos para proporcionar al modelo una representación concisa de la información.
- Datos, datos y más datos: gestionar, verificar, versionar y limpiar cuidadosamente las fuentes de datos. Calidad > cantidad. Datos basura = RAG basura.
- Evaluación de la recuperación: puede incluir
- Evaluar el rendimiento de la recuperación midiendo la proporción de documentos relevantes recuperados (precisión) y todos los documentos relevantes recuperados (recall); e
- Integrar evaluaciones humanas.
- Evaluar la generación: evaluar la fidelidad y la relevancia de la respuesta utilizando un marco de evaluación personalizado.
- Darse cuenta de que no siempre se necesita una base de datos vectorial.
Estrategias intermedias de optimización de implementaciones RAG
- Filtrado de metadatos: añade metadatos a los trozos para ayudar a procesar los resultados. Recuerda: similar ≠ relevante.
- Gestión de la información incorporada: estrategias para gestionar documentos que se actualizan con frecuencia o que se añaden recientemente; entre los retos se incluyen la indexación incremental y la clasificación dinámica de documentos.
- Fiabilidad: utiliza citas/atribuciones y emplea técnicas como la estimación de la confianza, la cuantificación de la incertidumbre y el análisis de errores para garantizar la precisión y fiabilidad del contenido generado.
- Aprovecha técnicas de búsqueda híbridas u otros tipos de índices: integra diferentes técnicas de búsqueda, como las búsquedas basadas en palabras clave y las búsquedas semánticas.
- Aplica transformaciones a la consulta: modifica la consulta del usuario para que se ajuste mejor a la información que se necesita de las fuentes de datos. Los usuarios no siempre saben lo que quieren. Las transformaciones de consulta pueden incluir estrategias como la incrustación hipotética de documentos:
- Que toma una consulta, genera una respuesta hipotética y luego utiliza ambas para la búsqueda de incrustación;
- descomponiendo la consulta original en múltiples subconsultas o preguntas; y
- evaluando iterativamente la consulta en busca de la información que falta y generando la respuesta una vez que toda la información está disponible.
- Compensaciones: considera el equilibrio entre precisión, recuperación, cálculo/coste para optimizar el proceso de recuperación y generación.
- Estrategias avanzadas de fragmentación: experimenta con diferentes estrategias de fragmentación, como la recuperación por ventanas de frases y la recuperación por autofusión para mejorar la precisión y la relevancia.
- Reordena: reordena los documentos recuperados en función de su relevancia para la consulta del usuario.
Estrategias avanzadas de optimización de implementaciones RAG
- Ajuste fino del modelo: continúa el proceso de entrenamiento en un conjunto de datos más pequeño y específico para optimizar el rendimiento o ajuste fino para representar mejor las relaciones entre los puntos de datos. el ajuste fino en conjuntos de datos específicos del dominio puede a veces ayudar a entender el contexto.
- Personaliza los datos de entrenamiento incorporados etiquetándolos: el enfoque consiste en crear una matriz que se puede utilizar para multiplicar las incorporaciones. el producto de esta multiplicación es una «incorporación personalizada» que enfatizará mejor los aspectos del texto relevantes para su caso de uso».
- Enrutamiento de consultas: si tienes más de un índice o herramienta, enruta las subconsultas al índice o herramienta/llamada a la función adecuada.
- Recuperación múltiple: combina los resultados de varios agentes de recuperación (¿y generadores?) para mejorar la calidad y fidelidad globales.
- Compresión y filtrado contextual: aplica técnicas de compresión para reducir el tamaño del contexto conservando su pertinencia, y utiliza el filtrado para seleccionar la información más pertinente para el modelo.
- Autoconsulta: utiliza el resultado del modelo como consulta para recuperar más información, que puede combinarse con la respuesta inicial para generar una respuesta más precisa.
- Jerarquías de documentos y grafos de conocimiento: utiliza las jerarquías de documentos y los grafos de conocimiento para mejorar la organización y recuperación de la información.
Esta información está basada en un tuit/X de shyamal.