

Google Gemini 1.5: prompts de 1 millón de tokens
Ayer OpenAI lanzó impresionantes avances de generación de vídeo AI con «Sora» pero Google también anunció cosas alucinantes con Gemini 1.5.
El anuncio de Google fue poco emocionante frente a los vídeos potencialmente virales de OpenAI; pero Gemini 1.5 entiende videos además de generarlos.
Gemini 1.5 puede manejar hasta 1 millón de tokens (10 millones de forma expermiental) frente a las ventanas de contexto más grandes hasta ahora de unos 200.000 tokens.
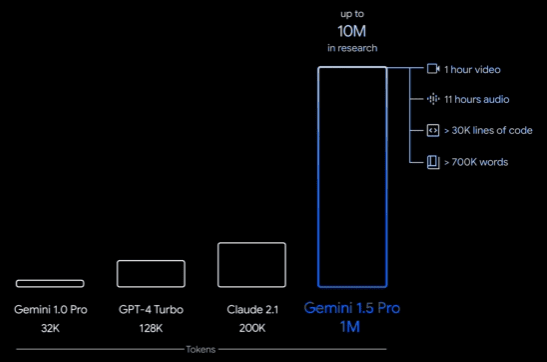
Eso significa que puede procesar 1 hora de vídeo o más de 700.000 palabras (más de 1.000 páginas) como prompt.
El paper de Google Gemini 1.5
En este informe Google presenta el último modelo de la familia Gemini, Gemini 1.5 Pro, un modelo multimodal de mezcla de expertos altamente eficiente desde el punto de vista computacional, capaz de recuperar y razonar sobre información detallada de millones de tokens de contexto, incluidos múltiples documentos largos y horas de vídeo y audio.
Gemini 1.5 Pro consigue una recuperación casi perfecta en tareas de recuperación de contextos largos en todas las modalidades con documentos largos, vídeos largos y contextos largos, e iguala o supera a Gemini 1.0 Ultra en un amplio conjunto de pruebas de referencia.
Al estudiar los límites de la capacidad de Gemini 1.5 Pro en contextos largos, se observa una mejora continua en la predicción del siguiente token y una recuperación casi perfecta (>99%) hasta al menos 10 millones de tokens, lo que supone un salto generacional con respecto a modelos existentes como Claude 2.1 (200k) y GPT-4 Turbo (128k).
Por último, hay que destacar nuevas y sorprendentes capacidades de los grandes modelos lingüísticos; cuando se le da un manual de gramática del kalamang, una lengua con menos de 200 personas que lo hablan en todo el mundo, el modelo aprende a traducir del inglés al kalamang a un nivel similar al de una persona que aprende del mismo contenido.
¿Para qué sirve un prompt de 1 millón de tokens?
Analizar documentos de gran tamaño
A partir de las 402 páginas de transcripciones de la misión Apolo 11, Gemini 1.5 puede diseccionar y razonar sobre conversaciones y eventos detallados, lo que indica su destreza en el manejo de documentos complejos y extensos.
Con el texto completo de Los Miserables en el prompt (1.382 páginas, 732.000 tokens), Gemini 1.5 Pro es capaz de identificar y localizar cualquier escena con un esquema dibujado a mano.
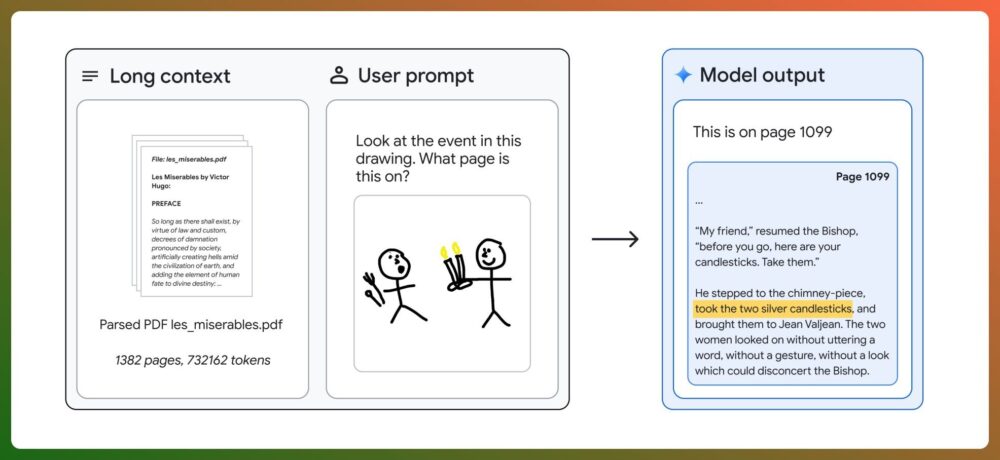
Los índices de recuperación, que miden la calidad real del uso de la ventana contextual, son impresionantes.
Visualización y comprensión de vídeos
En el análisis de una película muda de Buster Keaton de 44 minutos de duración, Gemini 1.5 destaca en la interpretación y el razonamiento sobre contenidos en diversos formatos, incluido el vídeo.
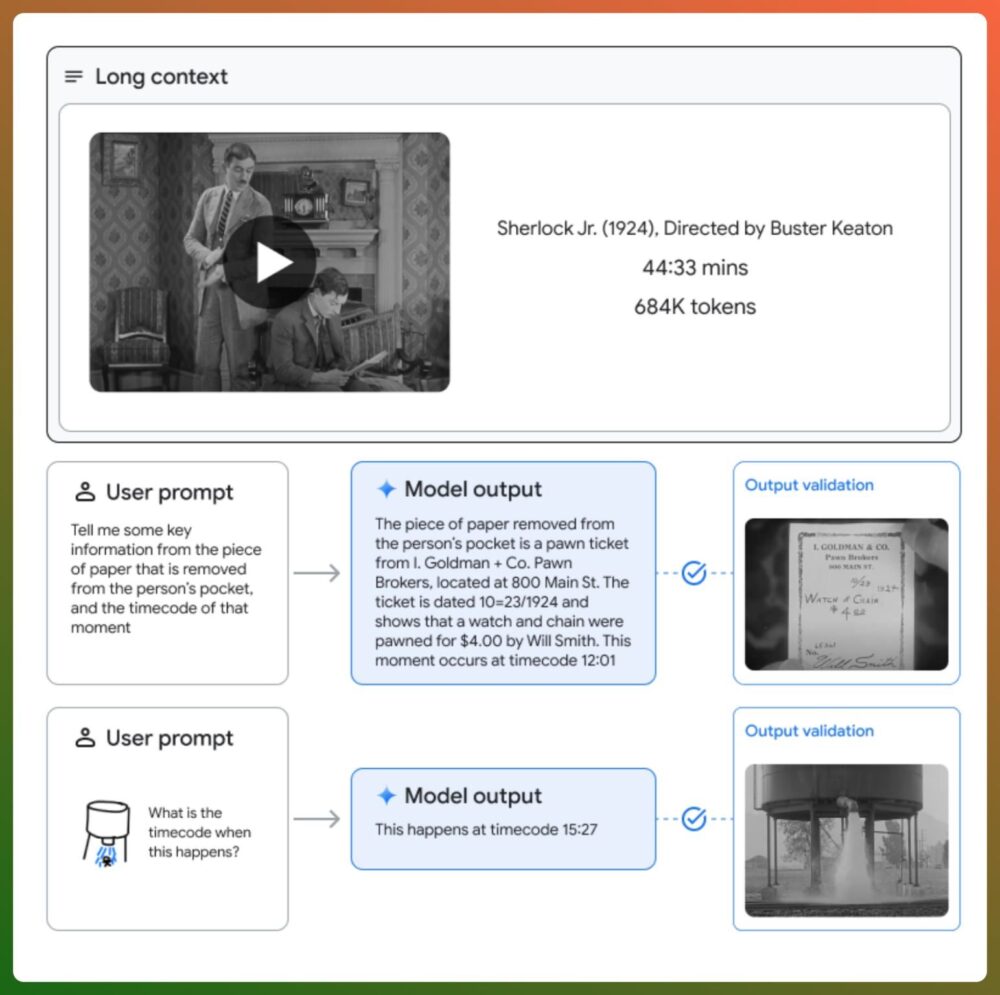
Puede encontrar una palabra secreta «oculta» en un documental sobre AlphaGo.

Géminis 1.5 es capaz de ver vídeos y resumirlos. ¡Bienvenidos al futuro!
Análisis de código y resolución de problemas
Mediante la capacidad de navegar a través de más de 100.000 líneas de código, Gemini 1.5 ofrece soluciones y explicaciones perspicaces, demostrando su eficacia en tareas de desarrollo y depuración de software.
Llega a analizar más de 700 archivos de código fuente de una sola vez.
Innovaciones en traducción de idiomas
Gemini 1.5 aprendió a traducir el inglés al kalamang, un leguaje que hablan menos de 200 personas en el mundo, lo que ilustra su potencial en el aprendizaje y la traducción de idiomas sin necesidad de un ajuste previo.
Gemini 1.5 puede aprender un idioma en un solo prompt.
Construye y experimenta con Google Gemini 1.5
A partir de ayer Gemini 1.5 Pro está disponible a través de AI Studio y Vertex AI.
Se lanza 1.5 Pro con una ventana de contexto estándar de 128.000 tokens que se podrá aumentar hasta 1 millón de tokens a medida que se mejore el modelo.
¡Bienvenidos al futuro!
Esta información está basada el paper de Google: «Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context» y la entrada de blog «Introducing Gemini 1.5«.


