La importancia de los datos de entrenamiento para la IA
¿Qué importancia tienen los datos de entrenamiento en IA? Mucha. Meta quería adquirir una importante editorial de libros para ello.
O sea que Meta quería adquirir una empresa sólo por los datos para entrenar su inteligencia artificial.
Meta estuvo estudiando la compra de la editorial Simon & Schuster para los datos de entrenamiento de la IA y sopesó el uso de datos en línea protegidos por derechos de autor, incluso si eso significaba enfrentarse a demandas.
Y más sobre los datos sintéticos como solución: «OpenAI, Google y otras empresas están explorando el uso de su Inteligencia Artificial para crear más datos. El resultado sería lo que se conoce como datos «sintéticos». La idea es que los modelos de I.A. generen nuevos textos que luego puedan utilizarse para construir una I.A. mejor. Pero los datos sintéticos son arriesgados porque los modelos de I.A. pueden cometer errores. Confiar en esos datos puede agravar esos errores».
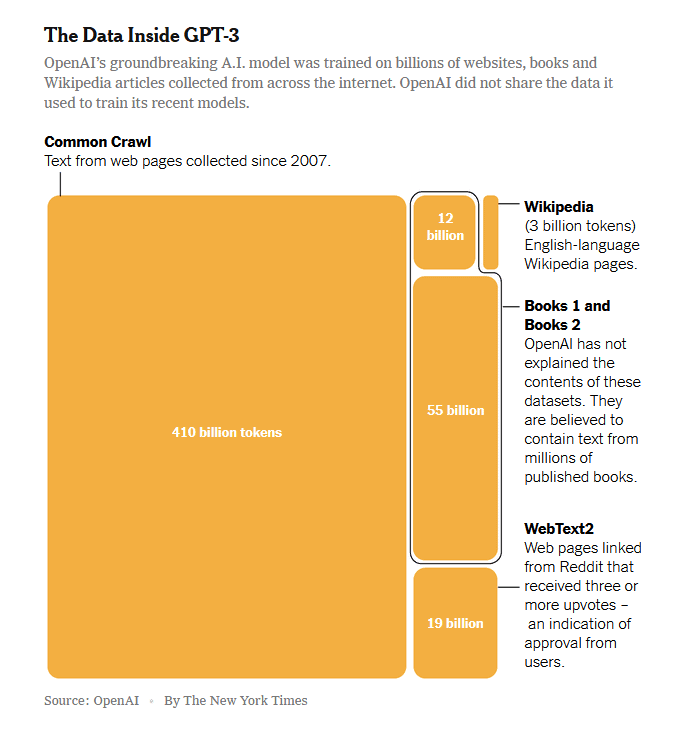
Cuantos más datos, mejor.
El éxito de la inteligencia artificial depende de los datos. Esto se debe a que los modelos de Inteligencia Artificial se vuelven más precisos y más parecidos a los humanos con más datos.
Del mismo modo que un estudiante aprende leyendo más libros, ensayos y otra información, los grandes modelos lingüísticos -los sistemas que son la base de los chatbots- también se vuelven más precisos y potentes si se les alimenta con más datos.
Algunos grandes modelos lingüísticos, como el GPT-3 de OpenAI, lanzado en 2020, se entrenaron con cientos de miles de millones de «tokens», que son básicamente palabras o fragmentos de palabras. Los grandes modelos lingüísticos más recientes se han entrenado con más de tres billones de tokens.
Los datos en línea son un recurso precioso y finito
Las empresas tecnológicas están agotando los datos disponibles públicamente en línea para desarrollar sus modelos de Inteligencia Artificial más rápido de lo que se producen nuevos datos. Según una predicción, los datos digitales de alta calidad se habrán agotado en 2026.
En la carrera por conseguir más datos, OpenAI, Google y Meta están recurriendo a nuevas herramientas, cambiando sus condiciones de servicio y entablando debates internos.
En OpenAI, los investigadores crearon en 2021 un programa que convertía el audio de los vídeos de YouTube en texto y luego introducía las transcripciones en uno de sus modelos de Inteligencia Artificial, lo que iba en contra de las condiciones de servicio de YouTube, según explicaron personas conocedoras del asunto.
Nota aclarativa: El New York Times ha demandado a OpenAI por utilizar sin permiso artículos periodísticos protegidos por derechos de autor para el desarrollo de la inteligencia artificial.
Información basada el artículo de NYT: «Four Takeaways on the Race to Amass Data for A.I.«