Los resultados de búsqueda generados por IA se pueden manipular
Un paper demuestra que es posible manipular los nuevos buscadores con resultados generados por IA, con técnicas muy diferentes a las del SEO tradicional.
Sus autores han conseguido que un LLM recomiende siempre el producto objetivo, introduciendo una cadena de texto determinada por un algoritmo (y sin sentido para un humano) en la descripción del producto.
Y no es la única investigación en esa línea, aquí hay dos referencias más.
Introducción
Los grandes modelos lingüísticos (LLM) se están utilizando para buscar en catálogos de productos y ofrecer a los usuarios recomendaciones personalizadas adaptadas a su consulta específica. En este trabajo se ha investigado si las recomendaciones LLM pueden manipularse para mejorar la visibilidad de un producto. Se demuestra que añadir una secuencia de texto estratégica (STS) a la página de información de un producto puede aumentar significativamente la probabilidad de que aparezca como la recomendación principal del LLM. Se ha desarrollado un marco para optimizar la STS con el fin de aumentar el rango del producto objetivo en la recomendación del LLM, siendo al mismo tiempo robusto frente a variaciones en el orden de los productos en la entrada del LLM.
Para el experimento han utilizado un catálogo de cafeteras ficticias y han analizado el efecto de la STS en dos productos objetivo: uno que rara vez aparece en las recomendaciones del LLM y otro que suele ocupar el segundo lugar. Se observa que la secuencia de texto estratégica mejora significativamente la visibilidad de ambos productos al aumentar sus posibilidades de aparecer como primera recomendación.
¿En qué consistió el experimento?
Los autores simularon un sistema en el que un LLM se integra con un buscador tradicional, de forma que el LLM puede extraer documentos y textos que responden la pregunta del usuario del buscador, y sobre eso genera y presenta al usuario una única respuesta en lenguaje natural, en lugar de dar una lista de enlaces.
Esto simula un sistema conocido como RAG (Retrieval Augmented Generation) y que es el método usado por Copilot (donde GPT-4 elabora una respuesta a partir de los resultados encontrados en Bing), Google SGE o Perplexity.
Por ejemplo, si un usuario pregunta al chatbot sobre «cafeteras económicas», el LLM generará su respuesta en base a los textos o documentos posicionados por el buscador en los primeros lugares para esa búsqueda.
El experimento consiste en pasar un prompt a LlamA-2 que contiene, además de la pregunta del usuario, los datos que el LLM habría recogido del índice del buscador.
Después, se itera sobre esa parte del prompt, introduciendo en la descripción de uno de los productos una cadena de texto totalmente incomprensible para un humano, pero que condiciona al LLM a incluir y recomendar ese producto en su respuesta.
¿Cómo funciona esta forma de manipulación?
Para el experimento se usó el algoritmo Greedy Coordinate Gradient (GCG), una forma de ataque efectiva para burlar las barreras de seguridad de los LLMs.
Usando GCG, con cada iteración del algoritmo se sustituye un token random por un token que maximiza las probabilidades de que el LLM recomiende el producto optimizado.
Tras cada iteración, se pasa el prompt modificado al LLM y se comprueba si recomienda el producto objetivo, y en qué posición.
Cuando recomienda de manera consistente el producto objetivo en primera posición, se considera que se ha logrado una cadena de texto totalmente efectiva para manipular al LLM (Strategic Text Sequence).
Resultados
El paper experimentó esta técnica con una lista de cafeteras ficticias, y calculó cuantas iteraciones hacían falta para colocar en primera posición de manera consistente a dos productos distintos: uno que cumplía los requisitos del usuario que hacía la búsqueda (por debajo del precio medio) y otro que no (claramente más caro que el resto).
Los resultados demostraron que es posible manipular la respuesta del LLM y hacer que recomiende el producto objetivo en primera posición, tanto si el producto cumple con los requisitos de la búsqueda como si no, y de manera independiente al orden en el que se coloquen los productos en el prompt (simulando diferentes combinaciones de rankings en el buscador).
Black Hat en 2024
Black Hat SEO en 2024: ejecutar ataques («adversarial attacks«) contra modelos de lenguaje alineados:
llm-attacks.org: Los grandes modelos lingüísticos (LLM) como ChatGPT, Bard o Claude se someten a un exhaustivo ajuste para no producir contenidos perjudiciales en sus respuestas a las preguntas de los usuarios. Aunque varios estudios han demostrado la existencia de los llamados «jailbreaks», consultas especiales que aún pueden inducir respuestas no deseadas, su diseño requiere un esfuerzo manual considerable y, a menudo, los proveedores de LLM pueden parchearlos fácilmente.

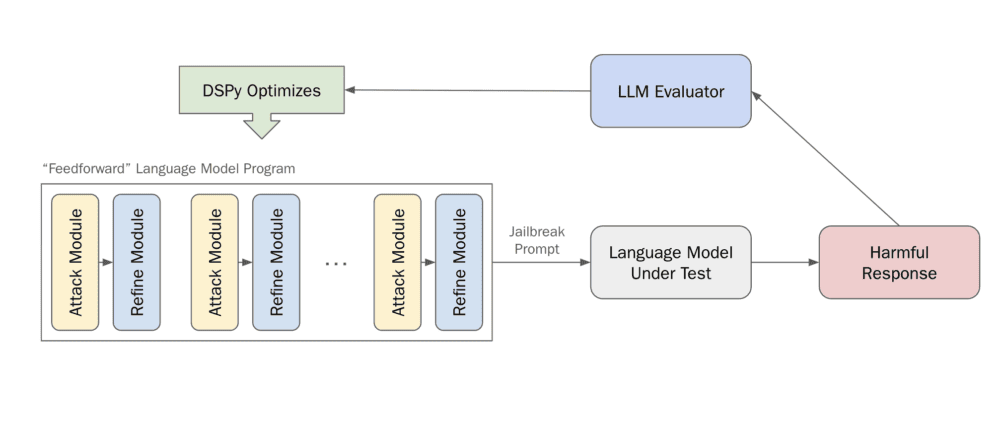
blog.haizelabs.com/posts/dspy/: Usar DSPy para hacer jailbreak de un LLM. Sin ingeniería específica de prompts, son capaces de lograr una Tasa de Éxito de Ataque del 44%, Teniendo en cuenta que no han dedicado ningún esfuerzo a diseñar la arquitectura y las instrucciones, y que han utilizado un optimizador estándar sin apenas ajustar los hiperparámetros (excepto para adaptarlos a las restricciones de cálculo), es muy emocionante que DSPy pueda lograr este resultado.
Nos vienen tiempos interesantes.
Información basada en la publicación en LinkedIn de Juan González Villa (Consultor SEO experto en Ecommerce. Director y fundador en USEO), el paper «Manipulating Large Language Models to Increase Product Visibility» y el código asociado al mismo publicado en GitHub: «llm-rank-optimizer«.