Meta anuncia V-JEPA que no genera videos pero aprende de ellos
Ayer Meta ha anunciado V-JEPA cuyo foco es justo el de aprender de los videos; no es un modelo generativo porque su foco está en entender.
El día de ayer fue un día lleno de novedades relacionadas con la inteligencia artificial generativa.
Meta presentó V-JEPA como el siguiente paso hacia la visión de Yann LeCun de la inteligencia artificial avanzada (advanced machine intelligence · AMI).
Video Joint Embedding Predictive Architecture (V-JEPA)
Ayer Facebook presentaba públicamente el modelo Video Joint Embedding Predictive Architecture (V-JEPA), un paso crucial en el avance de la inteligencia artificial hacia una comprensión más fundamentada del mundo.
- Este primer ejemplo de modelo del mundo físico destaca en la detección y comprensión de interacciones muy detalladas entre objetos.
- Siguiendo el espíritu de la ciencia abierta responsable, este modelo Meta lo publica bajo una licencia Creative Commons no comercial para que los investigadores puedan seguir explorándolo.
Como seres humanos, gran parte de lo que aprendemos sobre el mundo que nos rodea, sobre todo en las primeras etapas de nuestra vida, lo obtenemos a través de la observación. Por ejemplo, la tercera ley del movimiento de Newton: Incluso un bebé (o un gato) puede intuir, tras golpear varios objetos de una mesa y observar los resultados, que lo que sube tiene que bajar. No necesita horas de instrucción ni leer miles de libros para llegar a ese resultado. Tu modelo interno del mundo -una comprensión contextual basada en un modelo mental del mundo- predice esas consecuencias por ti, y es muy eficaz.
«V-JEPA es un paso hacia una comprensión más fundamentada del mundo para que las máquinas puedan lograr un razonamiento y una planificación más generalizados. Nuestro objetivo es construir una inteligencia de máquina avanzada que pueda aprender más como lo hacen los humanos, formando modelos internos del mundo que les rodea para aprender, adaptarse y forjar planes de manera eficiente al servicio de completar tareas complejas.»
Yann LeCun, Vicepresidente y Científico Jefe de Inteligencia Artificial de Meta, que propuso las Joint Embedding Predictive Architectures (JEPA) originales en 2022
V-JEPA es un modelo no generativo
V-JEPA es un modelo no generativo que aprende prediciendo partes perdidas o enmascaradas de un vídeo en un espacio de representación abstracto. Es similar a la Arquitectura de Predicción de Incrustación Conjunta de Imágenes (I-JEPA) de Meta, que compara representaciones abstractas de imágenes (en lugar de comparar los píxeles en sí). A diferencia de los enfoques generativos que tratan de rellenar cada píxel que falta, V-JEPA tiene la flexibilidad de descartar información impredecible, lo que conduce a una mejora de la eficiencia de la formación y de la muestra por un factor de entre 1,5x y 6x.
Dado que adopta un enfoque de aprendizaje autosupervisado, V-JEPA se entrena previamente con datos sin etiquetar. Las etiquetas sólo se utilizan para adaptar el modelo a una tarea concreta después del preentrenamiento. Este tipo de arquitectura resulta más eficaz que los modelos anteriores, tanto en lo que se refiere al número de ejemplos etiquetados necesarios como a la cantidad total de esfuerzo dedicado al aprendizaje incluso de los datos no etiquetados. Con V-JEPA, se ha observado un aumento de la eficacia en ambos frentes.
Con V-JEPA, se enmascara una gran parte de un vídeo para que el modelo sólo vea una pequeña parte del contexto. A continuación, se pide al predictor que rellene los espacios en blanco de lo que falta, no en términos de píxeles reales, sino como una descripción más abstracta en este espacio de representación.
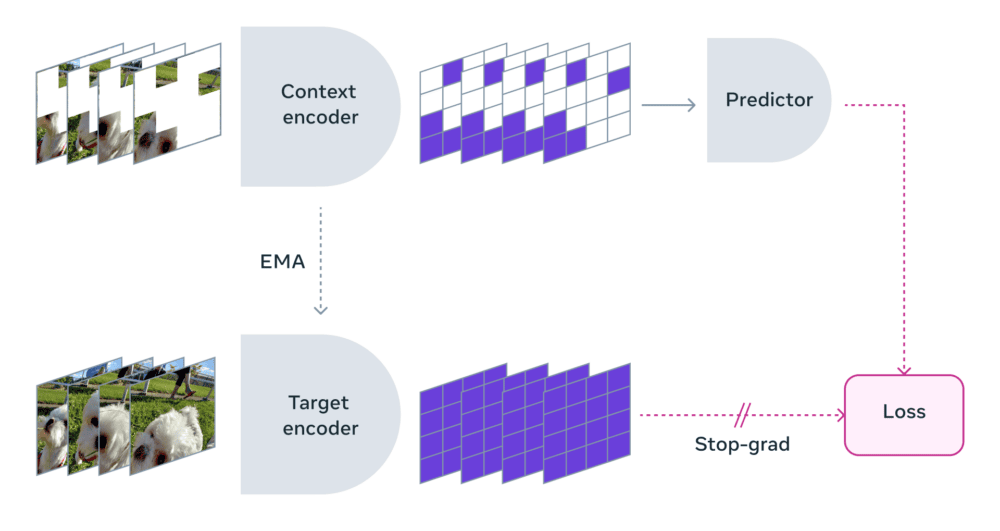
Metodología de enmascaramiento
A V-JEPA no se le entrenó para comprender un tipo concreto de acción. En su lugar, utilizó un entrenamiento autosupervisado en una serie de vídeos y aprendió una serie de cosas sobre cómo funciona el mundo. El equipo también tuvo muy en cuenta la estrategia de enmascaramiento: si no se bloquean grandes regiones del vídeo y se toman muestras aleatorias de fragmentos aquí y allá, la tarea resulta demasiado fácil y el modelo no aprende nada especialmente complicado sobre el mundo.
También es importante tener en cuenta que, en la mayoría de los vídeos, las cosas evolucionan con cierta lentitud a lo largo del tiempo. Si enmascaras una parte del vídeo pero sólo para un instante concreto y el modelo puede ver lo que vino inmediatamente antes y/o inmediatamente después, también facilitas demasiado las cosas y es casi seguro que el modelo no aprenderá nada interesante. Por eso, el equipo utilizó un enfoque en el que enmascaraba partes del vídeo tanto en el espacio como en el tiempo, lo que obliga al modelo a aprender y desarrollar una comprensión de la escena.
Predicciones eficaces
Hacer estas predicciones en el espacio de representación abstracta es importante porque permite al modelo centrarse en la información conceptual de alto nivel de lo que contiene el vídeo sin preocuparse por el tipo de detalles que suelen carecer de importancia para las tareas posteriores. Al fin y al cabo, si un vídeo muestra un árbol, lo más probable es que a ti no te preocupen los minuciosos movimientos de cada hoja.
Una de las razones por las que en Meta están entusiasmados con esta dirección es que V-JEPA es el primer modelo para vídeo que es bueno en «evaluaciones congeladas», lo que significa que se hace todo el preentrenamiento autosupervisado en el codificador y el predictor, y luego no volvemos a tocar esas partes del modelo. Cuando se quiere aprender una nueva habilidad, sólo hay que entrenar una pequeña capa ligera especializada o una pequeña red encima, lo que resulta muy eficiente y rápido.
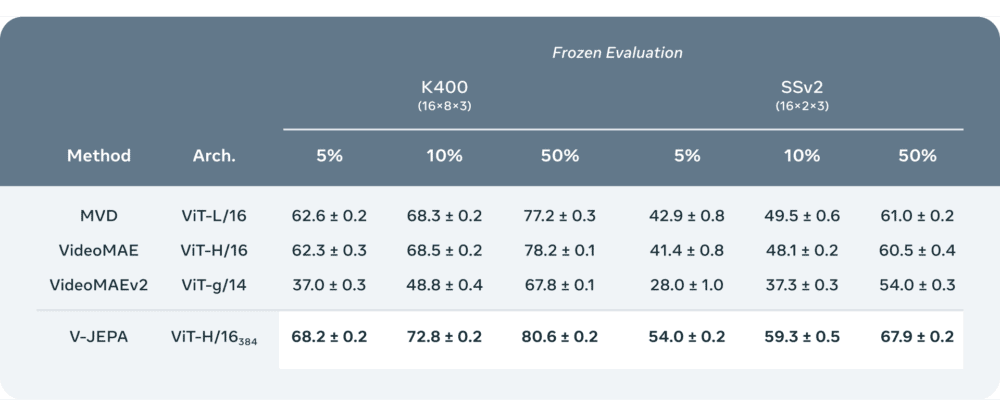
Los trabajos anteriores tenían que hacer un ajuste fino completo, lo que significa que después de preentrenar el modelo, cuando se quiere que el modelo sea realmente bueno en el reconocimiento de acciones finas mientras se está adaptando el modelo para asumir esa tarea, hay que actualizar los parámetros o los pesos en todo el modelo. Y entonces el modelo se especializa en esa tarea y ya no sirve para nada más. Si quieres enseñar al modelo una tarea diferente, tienes que utilizar datos diferentes, y tienes que especializar todo el modelo para esta otra tarea. Con V-JEPA se puede preentrenar el modelo una vez sin datos etiquetados, arreglarlo, y luego reutilizar esas mismas partes del modelo para varias tareas diferentes, como la clasificación de acciones, el reconocimiento de interacciones finas entre objetos y la localización de actividades.
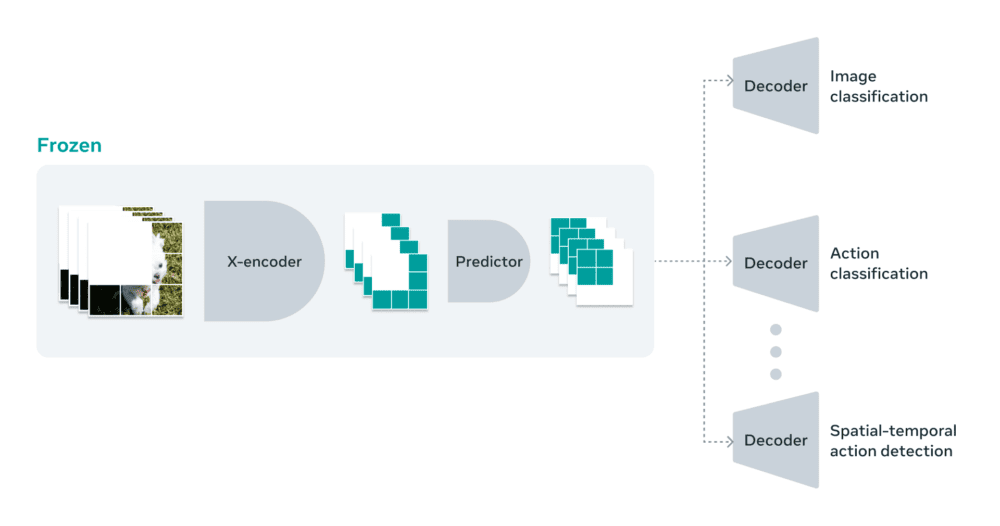
Vías para futuras investigaciones
Aunque la «V» de V-JEPA significa «vídeo», hasta ahora sólo tiene en cuenta el contenido visual de los vídeos. El siguiente paso es un enfoque más multimodal, por lo que se está estudiando detenidamente la posibilidad de incorporar el audio junto con los elementos visuales.
Como prueba de concepto, el modelo V-JEPA actual destaca en las interacciones detalladas entre objetos y en la distinción de las interacciones detalladas entre objetos que se producen a lo largo del tiempo. Por ejemplo, si el modelo tiene que distinguir entre alguien que deja un bolígrafo, alguien que lo coge y alguien que finge dejar el bolígrafo pero no lo hace, V-JEPA es bastante bueno en comparación con los métodos anteriores para esa tarea de reconocimiento de acciones de alto grado. Sin embargo, esas cosas funcionan en escalas de tiempo relativamente cortas. Si le enseñas a V-JEPA un clip de vídeo de unos segundos, quizá hasta 10 segundos, es genial para eso. Así que otro paso importante para Meta es pensar en la planificación y en la capacidad del modelo para hacer predicciones en un horizonte temporal más largo.
Este es el camino hacia la advanced machine intelligence (AMI)
Hasta la fecha, el trabajo con V-JEPA se ha centrado principalmente en la percepción, es decir, en comprender el contenido de varias secuencias de vídeo para obtener cierto contexto sobre el mundo que nos rodea. El predictor de esta Arquitectura Predictiva de Incrustación Conjunta sirve como modelo inicial del mundo físico: No es necesario ver todo lo que ocurre en el fotograma, y puede decirnos conceptualmente lo que está ocurriendo allí. Como siguiente paso, Meta quiere mostrar cómo puede utilizar este tipo de predictor o modelo del mundo para la planificación o la toma de decisiones secuenciales.
En Meta saben que es posible entrenar a los modelos JEPA con datos de vídeo sin necesidad de una fuerte supervisión y que pueden ver vídeos como lo haría un bebé -observando el mundo pasivamente-, aprendiendo un montón de cosas interesantes sobre cómo entender el contexto de esos vídeos de tal forma que, con una pequeña cantidad de datos etiquetados, se puede adquirir rápidamente una nueva tarea y la capacidad de reconocer diferentes acciones.
V-JEPA es un modelo de investigación, y se están explorando varias aplicaciones futuras. Por ejemplo, se espera que el contexto que proporciona V-JEPA pueda ser útil para el trabajo de IA incorporada, así como para el trabajo de creación de un asistente de IA contextual para las futuras gafas de RA.