

Mistral Large 2, un modelo open source que compite con Llama
A finales de julio de 2024 se presentó Mistral Large 2, más capaz en generación de código, matemáticas y razonamiento.
Después del lanzamiento de la versión 1 en abril de 2024 («Mistral AI lanza una IA sin censura que sabe matemáticas«) ahora nos llega la versión 2 de Mistral. Una versión con soporte multilingüe sólido y significativamente más capaz en generación de código, matemáticas y razonamiento.
Y llega a los pocos días el lanzamiento del modelo opensource de IA de META: «Meta lanza Llama 3.1, el modelo de IA Open Source más potente«. Dos modelos open source potentes y en competencia.
Mistral Large 2
Mistral Large 2 tiene una ventana de contexto de 128k y es compatible con docenas de idiomas, como francés, alemán, español, italiano, portugués, árabe, hindi, ruso, chino, japonés y coreano, además de más de 80 lenguajes de programación, como Python, Java, C, C++, JavaScript y Bash.
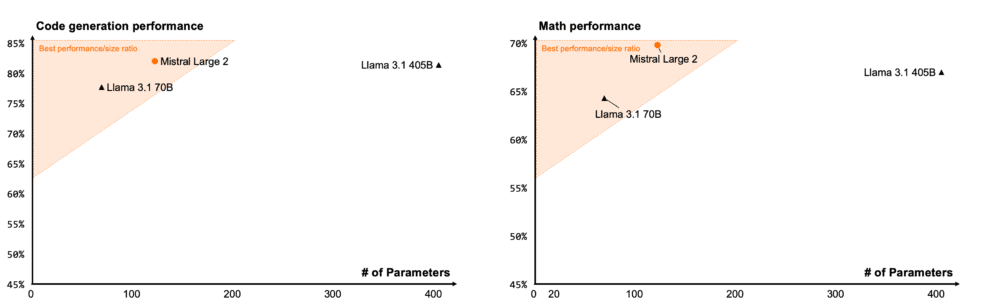
Mistral Large 2 está diseñado para la inferencia en un único nodo con aplicaciones de contexto largo en mente: su tamaño de 123.000 millones de parámetros le permite funcionar con un gran rendimiento en un único nodo.
Mistral 2: rendimiento excelente en programación y matemáticas
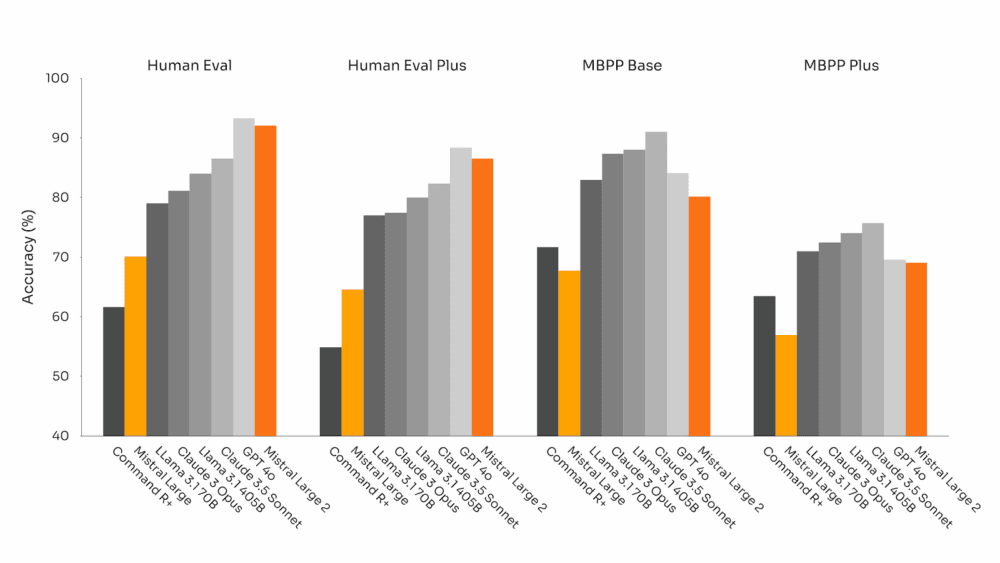
Tras la experiencia con Codestral 22B y Codestral Mamba, han entrenado Mistral Large 2 con código. Mistral Large 2 supera ampliamente al anterior Mistral Large y rinde a la par que modelos punteros como GPT-4o, Claude 3 Opus y Llama 3 405B.
Mistral 2: Mejor razonamiento y menos alucinaciones
También se ha dedicado un gran esfuerzo a mejorar la capacidad de razonamiento del modelo. Uno de los objetivos principales de la formación ha sido reducir al mínimo la tendencia del modelo a «alucinar» o generar información plausible pero incorrecta o irrelevante. Esto se ha conseguido ajustando el modelo para que sea más cauteloso y perspicaz en sus respuestas, garantizando que proporcionara resultados fiables y precisos.
Además, el nuevo Mistral Large 2 está entrenado para reconocer cuándo no encuentra soluciones o no dispone de información suficiente para dar una respuesta fiable. Este compromiso con la precisión se refleja en la mejora del rendimiento del modelo en las pruebas matemáticas más populares, lo que demuestra su mayor capacidad de razonamiento y resolución de problemas:
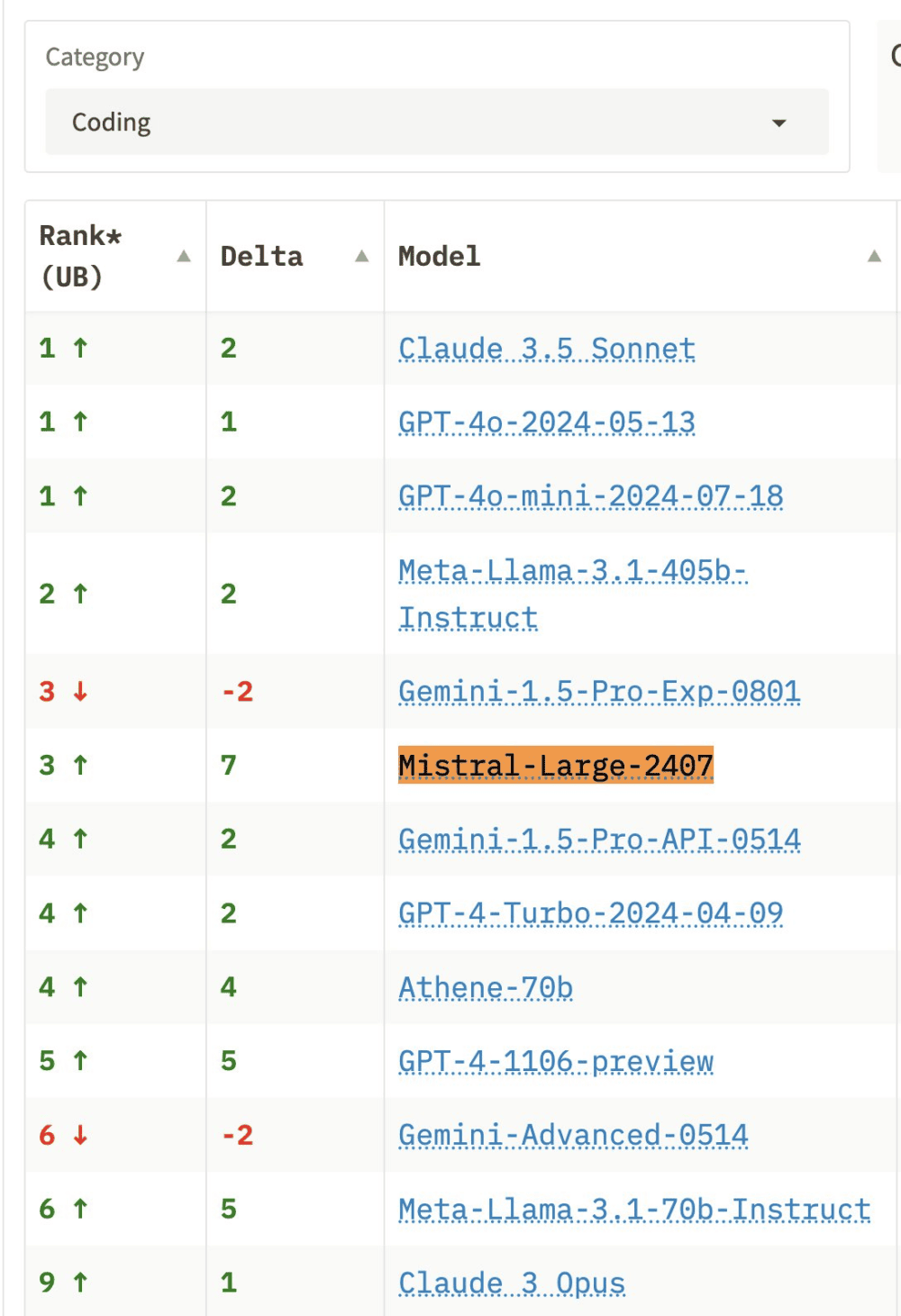
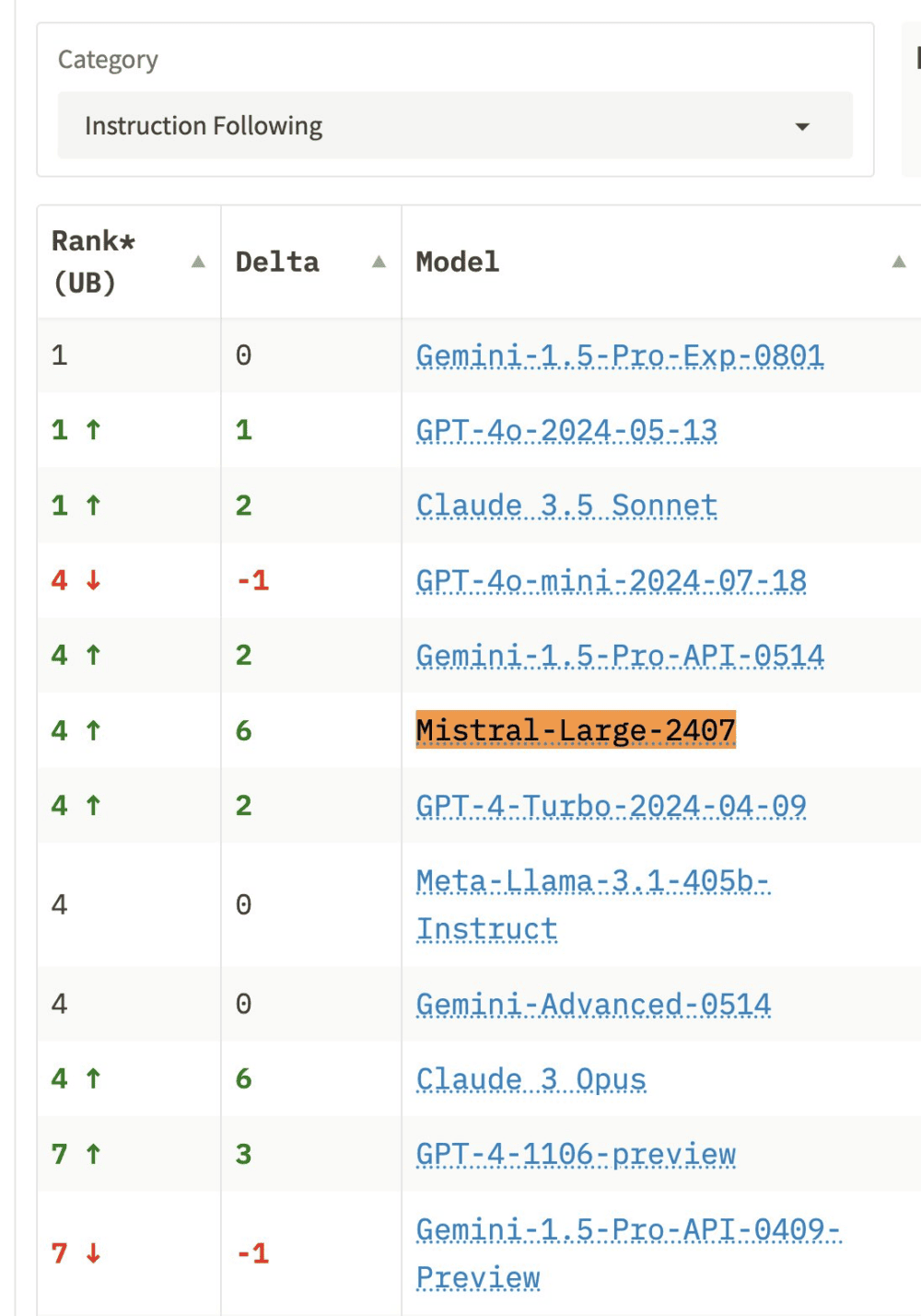
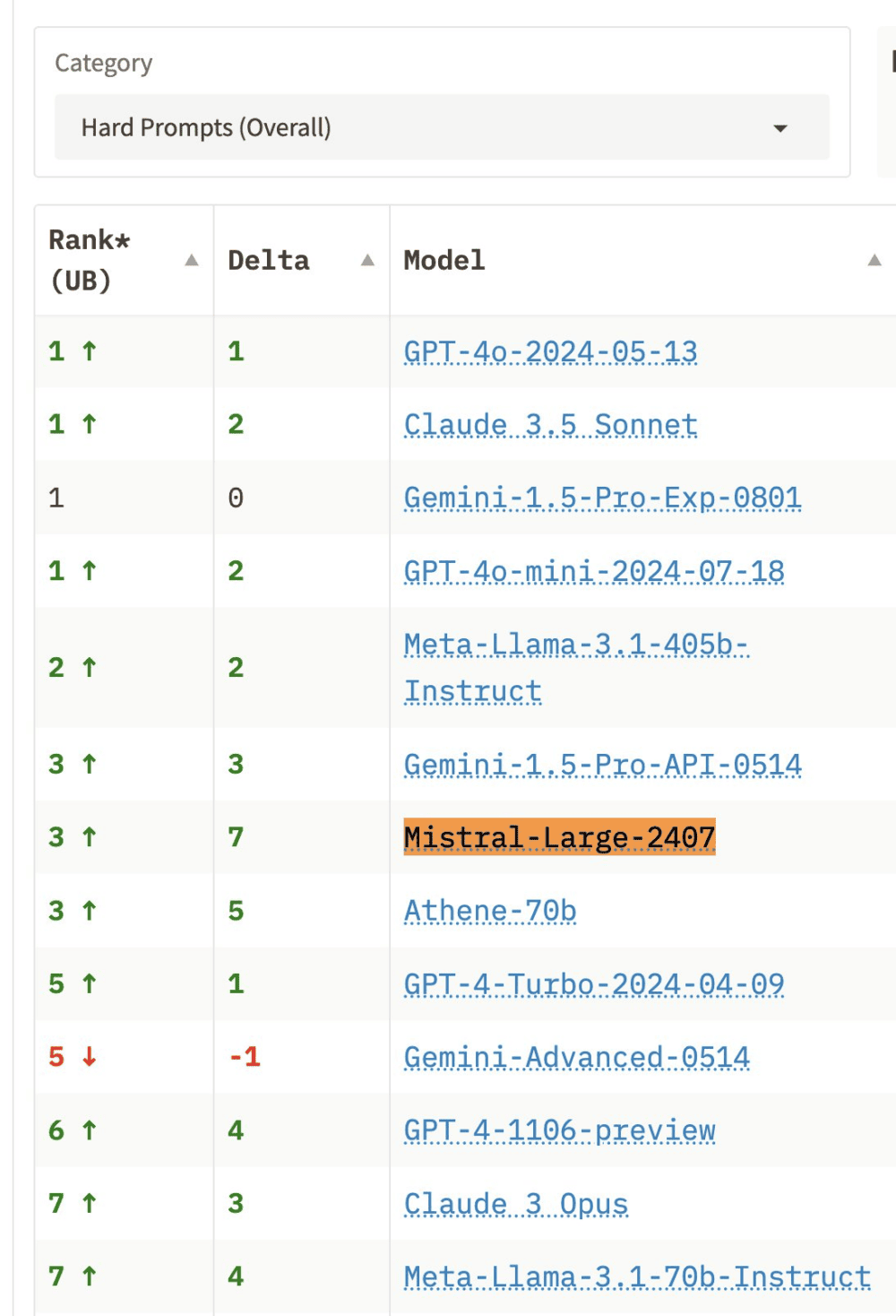
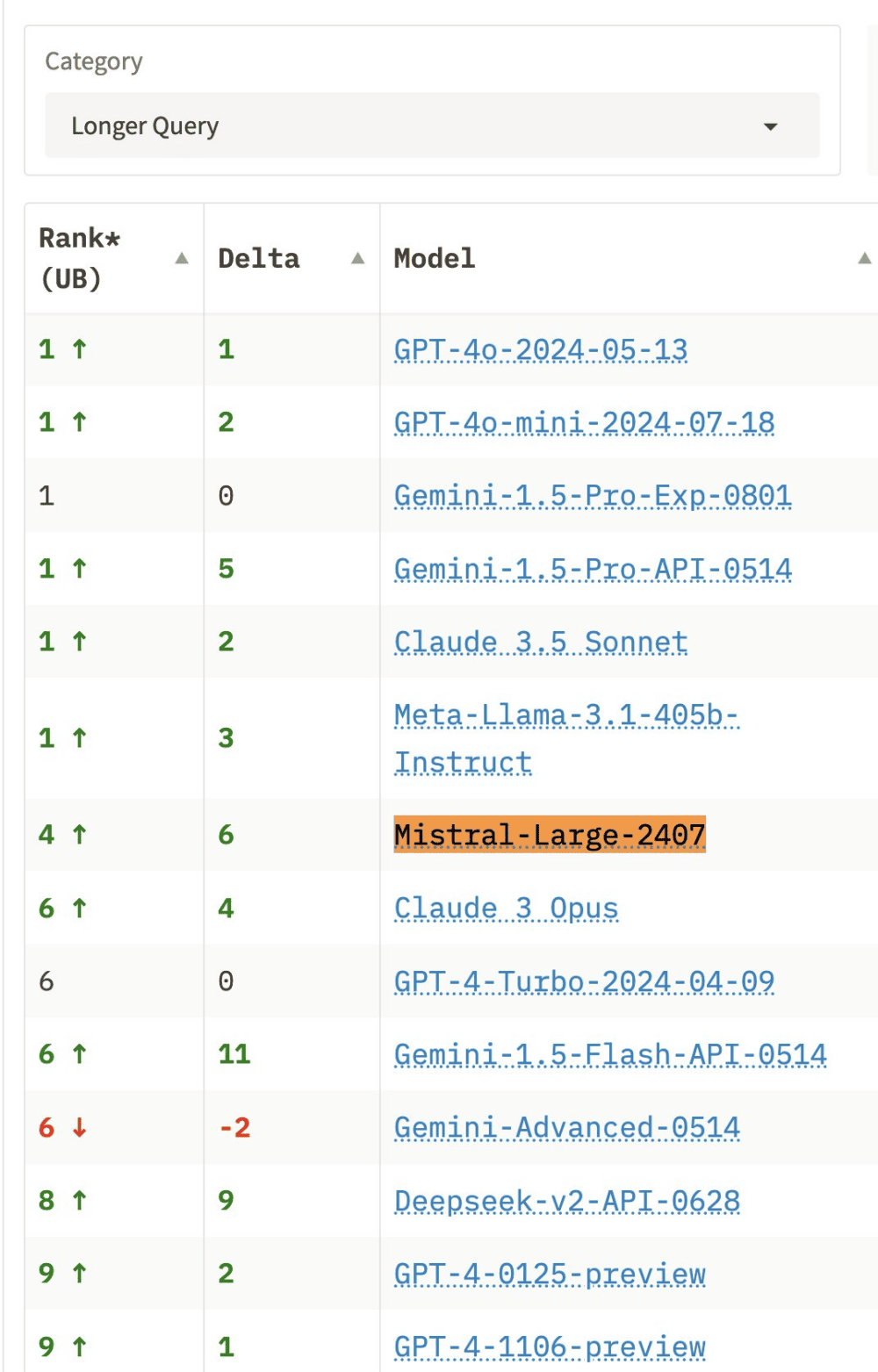
Rendimiento en las comparativas de lmsys.org
En la comparativa de más de 50 LLM (GPT-4/Claude/Gemini/Llamas) de lmsys.org el rendimiento de Mistral 2 es es excelente en las categorías de creación de código de programación («coding«), preguntas difíciles («hard prompts – overall«) y consultas más largas («longer query«), donde supera a GPT4-Turbo y Claude 3 Opus. También va muy bien en seguimiento de instrucciones («instruction following«), donde se sitúa por encima de Llama 3.1 405B.
Información basada en la publicación


