OpenAI desarrolló Whisper para transcribir vídeos de YouTube
Según el NYT, OpenAI desarrolló Whisper para transcribir vídeos de YouTube y entrenar GPT-4 con la transcripción de un millón de horas de vídeos.
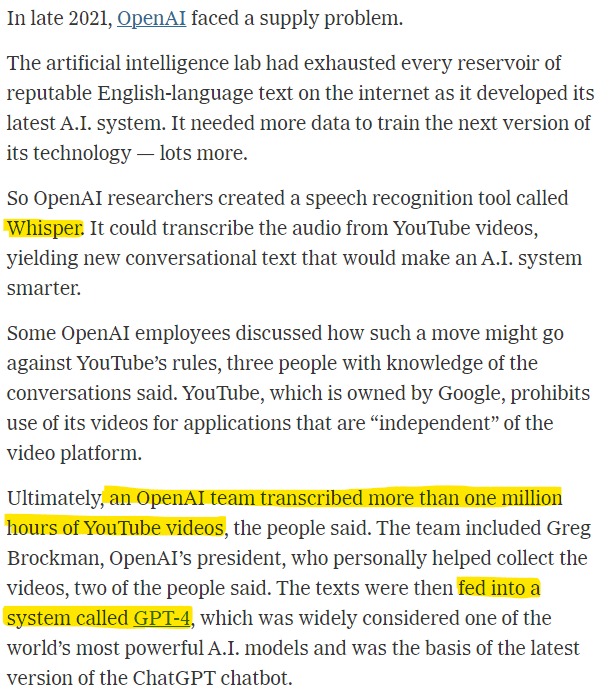
A finales de 2021, OpenAI se enfrentaba a un problema de suministro.
El laboratorio de inteligencia artificial había agotado todas las reservas de textos fiables en inglés de Internet mientras desarrollaba su último sistema de inteligencia artificial. Necesitaba más datos para entrenar la siguiente versión de su tecnología, muchos más.
Así que los investigadores de OpenAI crearon una herramienta de reconocimiento de voz llamada Whisper. Podía transcribir el audio de los vídeos de YouTube y generar un nuevo texto conversacional que haría más inteligente al sistema de inteligencia artificial.
Según tres personas conocedoras de las conversaciones, algunos empleados de OpenAI comentaron que esta medida podría ir en contra de las normas de YouTube. YouTube, propiedad de Google, prohíbe el uso de sus vídeos para aplicaciones «independientes» de la plataforma de vídeos.
Al final, un equipo de OpenAI transcribió más de un millón de horas de vídeos de YouTube. El equipo incluía a Greg Brockman, presidente de OpenAI, que ayudó personalmente a recopilar los vídeos, según dos de las personas. A continuación, los textos se introdujeron en un sistema llamado GPT-4, considerado uno de los modelos de inteligencia artificial más potentes del mundo y base de la última versión del chatbot ChatGPT.
La carrera por liderar la Inteligencia Artificial se ha convertido en una búsqueda desesperada de los datos digitales necesarios para hacer avanzar la tecnología. Para obtener esos datos, empresas tecnológicas como OpenAI, Google y Meta han recortado gastos, ignorado políticas corporativas y debatido la posibilidad de saltarse la ley, según un análisis de The New York Times.
El volumen de datos es crucial. Los principales sistemas de chatbot han aprendido de conjuntos de texto digital que abarcan hasta tres billones de palabras, es decir, aproximadamente el doble del número de palabras almacenadas en la Biblioteca Bodleian de la Universidad de Oxford, que recoge manuscritos desde 1602. Los datos más preciados, según los investigadores de Inteligencia Artificial, son la información de alta calidad, como libros y artículos publicados, que han sido cuidadosamente escritos y editados por profesionales.
Durante años, Internet -con sitios como Wikipedia y Reddit- fue una fuente de datos aparentemente inagotable. Pero a medida que avanzaba la Inteligencia Artificial, las empresas tecnológicas buscaron más repositorios.
Su situación es urgente. Las empresas tecnológicas podrían acabar con los datos de alta calidad de Internet en 2026.
Información basada en artículo del New York Times «How Tech Giants Cut Corners to Harvest Data for A.I. – OpenAI, Google and Meta ignored corporate policies, altered their own rules and discussed skirting copyright law as they sought online information to train their newest artificial intelligence systems.«