Microsoft lanza Phi-3 Mini superando a Meta Llama-3 8B
Poco después de que Meta lanzará Llama-3 8B, Microsoft lanza Phi-3 Mini que es mejor en casi todos los benchmarks.
Pequeño pero potente: Phi-3 mini tiene un gran potencial
A veces, la mejor manera de resolver un problema complejo es tomar ejemplo de un libro infantil. Esa es la lección que aprendieron los investigadores de Microsoft al descubrir cómo meter más caña en un paquete mucho más pequeño.
El año pasado, después de pasarse el día pensando en posibles soluciones a los enigmas del aprendizaje automático, Ronen Eldan, de Microsoft, estaba leyendo cuentos a su hija cuando pensó: «¿Cómo ha aprendido esta palabra? ¿Cómo sabe conectar estas palabras?».
Eso llevó al experto en aprendizaje automático de Microsoft Research a preguntarse cuánto podría aprender un modelo de IA utilizando sólo palabras que pudiera entender un niño de 4 años y, en última instancia, a un innovador enfoque de entrenamiento que ha dado lugar a una nueva clase de pequeños modelos de lenguaje más capaces que prometen hacer la IA más accesible a más personas.
Los grandes modelos lingüísticos (LLM) han creado nuevas e interesantes oportunidades para ser más productivos y creativos con la IA. Pero su tamaño significa que pueden requerir importantes recursos informáticos para funcionar.
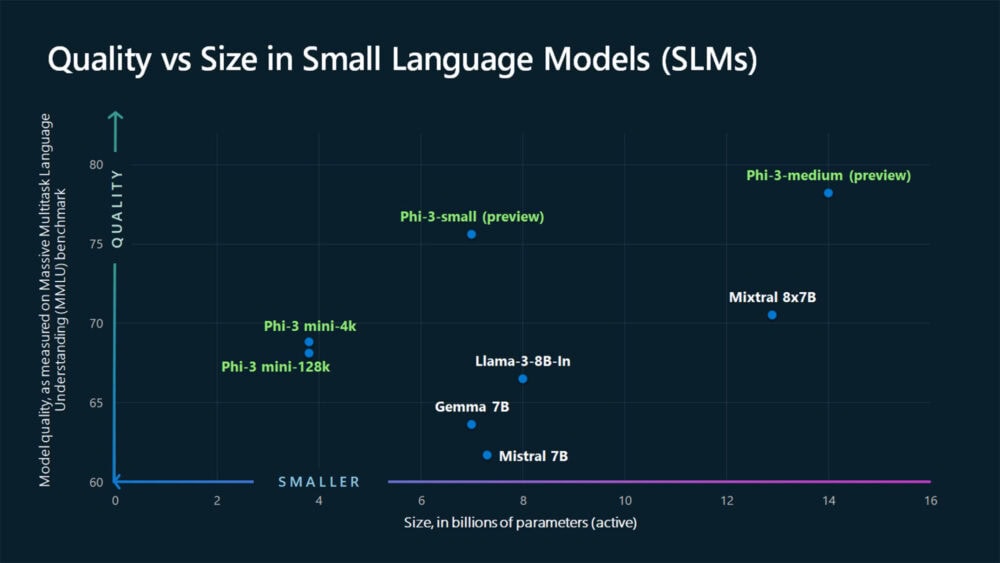
Aunque estos modelos seguirán siendo el patrón para resolver muchos tipos de tareas complejas, Microsoft ha estado desarrollando una serie de modelos lingüísticos pequeños (small language models · SLM) que ofrecen muchas de las mismas capacidades que los LLM, pero son más pequeños y se entrenan con cantidades menores de datos.
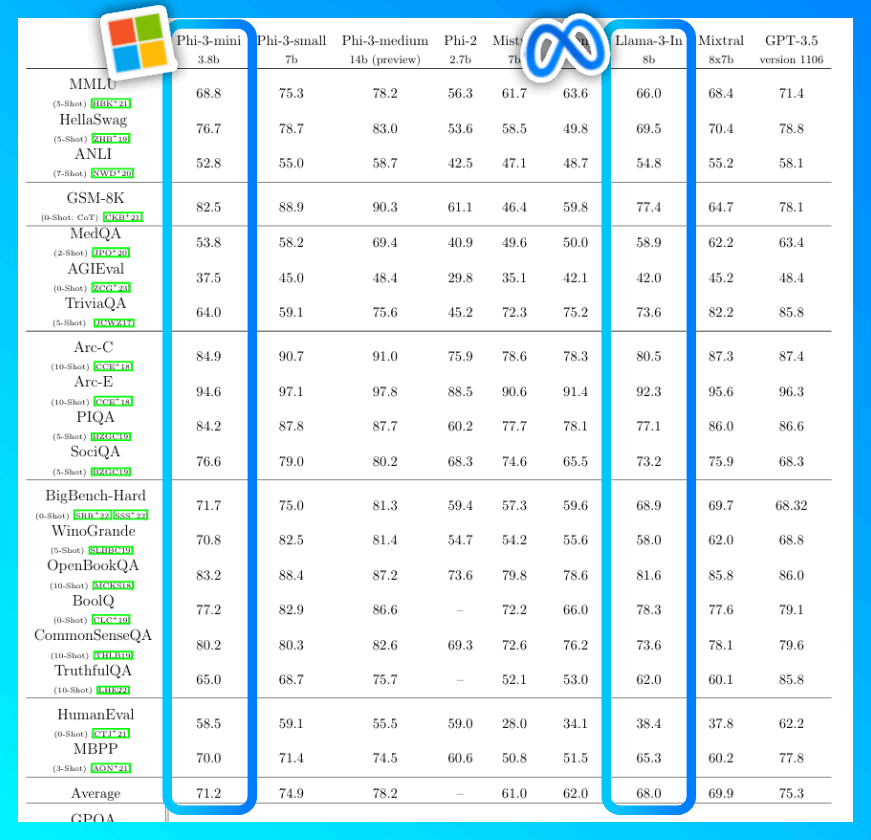
Microsoft ha anunciado hoy la familia de modelos abiertos Phi-3, los pequeños modelos lingüísticos más capaces y rentables del mercado. Los modelos Phi-3 superan a los del mismo tamaño y a los de tamaño inmediatamente superior en una serie de pruebas comparativas que evalúan las capacidades lingüísticas, de codificación y matemáticas, gracias a las innovaciones de entrenamiento desarrolladas por los investigadores de Microsoft.
Microsoft pone ahora a disposición del público el primero de esa familia de pequeños modelos lingüísticos más potentes: Phi-3-mini, que cuento con3.800 millones de parámetros y rinde mejor que modelos del doble de su tamaño, según la empresa.
A partir de hoy, estará disponible en el catálogo de modelos de IA de Microsoft Azure y en Hugging Face, una plataforma para modelos de aprendizaje automático, así como en Ollama, un framework ligero para ejecutar modelos en una máquina local. También estará disponible como microservicio de NVIDIA NIM con una interfaz API estándar que podrá implantarse en cualquier lugar.
Microsoft también ha anunciado que pronto se incorporarán nuevos modelos a la familia Phi-3 para ofrecer más opciones en términos de calidad y coste. Phi-3-small (7.000 millones de parámetros) y Phi-3-medium (14.000 millones de parámetros) estarán disponibles en breve en el catálogo de modelos de Azure AI y otros jardines de modelos.
Los modelos lingüísticos pequeños están diseñados para funcionar bien en tareas más sencillas, son más accesibles y fáciles de usar para organizaciones con recursos limitados y pueden ajustarse más fácilmente para satisfacer necesidades específicas.
«Lo que vamos a empezar a ver no es un cambio de modelos grandes a pequeños, sino un cambio de una categoría singular de modelos a una cartera de modelos en la que los clientes puedan decidir cuál es el mejor modelo para su situación»
Sonali Yadav, principal responsable de producto de Generative AI en Microsoft.
«Algunos clientes pueden necesitar sólo modelos pequeños, otros modelos grandes y muchos querrán combinar ambos de diversas maneras»
Luis Vargas, vicepresidente de IA de Microsoft.
La elección del modelo lingüístico adecuado depende de las necesidades específicas de una organización, la complejidad de la tarea y los recursos disponibles. Los modelos lingüísticos pequeños son muy adecuados para organizaciones que buscan crear aplicaciones que puedan ejecutarse localmente en un dispositivo (en lugar de en la nube) y en las que una tarea no requiera un razonamiento extenso o se necesite una respuesta rápida.
Los modelos lingüísticos grandes son más adecuados para aplicaciones que necesitan orquestar tareas complejas que implican razonamiento avanzado, análisis de datos y comprensión del contexto.
Los modelos lingüísticos pequeños también ofrecen soluciones potenciales para industrias y sectores regulados que se encuentran con situaciones en las que necesitan resultados de alta calidad pero quieren conservar los datos en sus propias instalaciones, afirmó Yadav.
Como los SLM pueden trabajar fuera de línea, más gente podrá poner a trabajar la IA de formas que antes no eran posibles.
Luis Vargas, vicepresidente de IA de Microsoft.
Por ejemplo, los SLM también podrían utilizarse en zonas rurales sin servicio de telefonía móvil. Pensemos en un agricultor que inspecciona los cultivos y detecta signos de enfermedad en una hoja o rama. Con un SLM con capacidad visual, el agricultor podría hacer una foto del cultivo en cuestión y obtener recomendaciones inmediatas sobre cómo tratar las plagas o enfermedades.
«Si estás en una parte del mundo que no tiene una buena red vas a poder tener experiencias de IA en tu dispositivo».
Luis Vargas, vicepresidente de IA de Microsoft.
El papel de los datos de alta calidad
Tal y como su nombre indica, en comparación con las LLM, las SLM son diminutas, al menos para los estándares de la IA. Phi-3-mini tiene «sólo» 3.800 millones de parámetros, una unidad de medida que se refiere a los botones algorítmicos de un modelo que ayudan a determinar su resultado. En cambio, los modelos lingüísticos más grandes son muchos órdenes de magnitud mayores.
Se creía que los enormes avances de la IA generativa propiciados por los grandes modelos lingüísticos se debían en gran medida a su enorme tamaño. Pero el equipo de Microsoft ha conseguido desarrollar modelos lingüísticos pequeños capaces de ofrecer resultados extraordinarios en un paquete diminuto. Este avance fue posible gracias a un enfoque muy selectivo de los datos de entrenamiento, que es donde entran en juego los libros infantiles.
Hasta ahora, el método estándar para entrenar grandes modelos lingüísticos consistía en utilizar grandes cantidades de datos de Internet. Se pensaba que era la única forma de satisfacer el enorme apetito de contenidos de este tipo de modelos, que necesitan «aprender» para entender los matices del lenguaje y generar respuestas inteligentes a las preguntas de los usuarios. Pero los investigadores de Microsoft tuvieron una idea diferente.
«En lugar de entrenar sólo con datos web sin procesar, ¿por qué no se buscan datos de altísima calidad?», se pregunta Sebastien Bubeck, Vicepresidente de Investigación Generativa de Inteligencia Artificial de Microsoft, que ha dirigido los esfuerzos de la empresa por desarrollar pequeños modelos lingüísticos más capaces. Pero, ¿dónde centrarse?
Inspirándose en el ritual de lectura nocturna de Eldan con su hija, los investigadores de Microsoft decidieron crear un conjunto de datos discretos a partir de 3.000 palabras, con un número aproximadamente igual de sustantivos, verbos y adjetivos. A continuación, pidieron a un gran modelo lingüístico que creara un cuento infantil utilizando un sustantivo, un verbo y un adjetivo de la lista, una petición que repitieron millones de veces durante varios días, generando millones de pequeños cuentos infantiles.
Bautizaron el conjunto de datos resultante como «TinyStories» y lo utilizaron para entrenar modelos lingüísticos muy pequeños de unos 10 millones de parámetros. Para su sorpresa, cuando se le pedía que creara sus propias historias, el pequeño modelo lingüístico entrenado con TinyStories generaba narraciones fluidas con una gramática perfecta.
A continuación, el experimento subió de nivel, por así decirlo. Esta vez, un grupo más amplio de investigadores utilizó para entrenar a Phi-1 datos públicos cuidadosamente seleccionados y filtrados en función de su valor educativo y la calidad de su contenido. Tras recopilar la información pública disponible en un conjunto de datos inicial, utilizaron una fórmula de estímulo y siembra inspirada en la empleada para TinyStories, pero la llevaron un paso más allá y la hicieron más sofisticada, de modo que pudiera captar un mayor número de datos. Para garantizar una alta calidad, filtraron repetidamente el contenido resultante antes de devolverlo a un LLM para su posterior síntesis. Así, a lo largo de varias semanas, crearon un corpus de datos lo suficientemente amplio como para entrenar un SLM más capaz.
«Se pone mucho cuidado en producir estos datos sintéticos», dice Bubeck refiriéndose a los datos generados por la IA, «revisándolos, asegurándose de que tienen sentido, filtrándolos. No nos quedamos con todo lo que producimos». Bautizaron este conjunto de datos como «CodeTextbook».
Los investigadores mejoraron aún más el conjunto de datos abordando la selección de datos como un profesor que desglosa conceptos difíciles para un alumno. «Como se trata de una lectura de material similar a un libro de texto, de documentos de calidad que explican las cosas muy, muy bien», explica Bubeck, «se facilita mucho la tarea del modelo lingüístico para leer y comprender este material».
Distinguir entre información de alta y baja calidad no es difícil para un ser humano, pero clasificar los más de un terabyte de datos que los investigadores de Microsoft determinaron que necesitarían para entrenar su SLM sería imposible sin la ayuda de un LLM.
«La potencia de la actual generación de modelos lingüísticos de gran tamaño es una herramienta que antes no teníamos para generar datos sintéticos», explica Ece Kamar, vicepresidente de Microsoft que dirige el laboratorio Microsoft Research AI Frontiers Lab, donde se desarrolló el nuevo método de entrenamiento.
Empezar con datos cuidadosamente seleccionados ayuda a reducir la probabilidad de que los modelos devuelvan respuestas no deseadas o inapropiadas, pero no es suficiente para evitar todos los posibles problemas de seguridad. Como en todos los lanzamientos de modelos de IA generativa, los equipos de producto y responsables de IA de Microsoft utilizaron un enfoque de varios niveles para gestionar y mitigar los riesgos en el desarrollo de los modelos Phi-3.
Por ejemplo, tras la formación inicial, proporcionaron ejemplos adicionales y comentarios sobre cómo deberían responder los modelos en condiciones ideales, lo que constituye una capa de seguridad adicional y ayuda al modelo a generar resultados de alta calidad. Cada modelo se somete también a evaluación, pruebas y red-teaming manual, en el que los expertos identifican y abordan las posibles vulnerabilidades.
Por último, los desarrolladores que utilicen la familia de modelos Phi-3 también pueden aprovechar un conjunto de herramientas disponibles en Azure AI para ayudarles a crear aplicaciones más seguras y fiables.
Información basada en la publicación oficial de Microsoft anunciando la disponibilidad del modelo «Tiny but mighty: The Phi-3 small language models with big potential«.