Utiliza la IA para realizar previsiones de pedidos de clientes
Las distribuidoras pueden utilizar la IA y el aprendizaje automático para predecir la un pedido futuro de un cliente para una SKU específica.
Mediante el uso de la Previsión del Próximo Pedido (NOF – Next Order Forecasting), los distribuidores pueden proporcionar a los clientes recomendaciones de productos y sugerir cantidades óptimas. Este artículo se basa en los conceptos descritos en la arquitectura de aprendizaje automático de muchos modelos.
Arquitectura
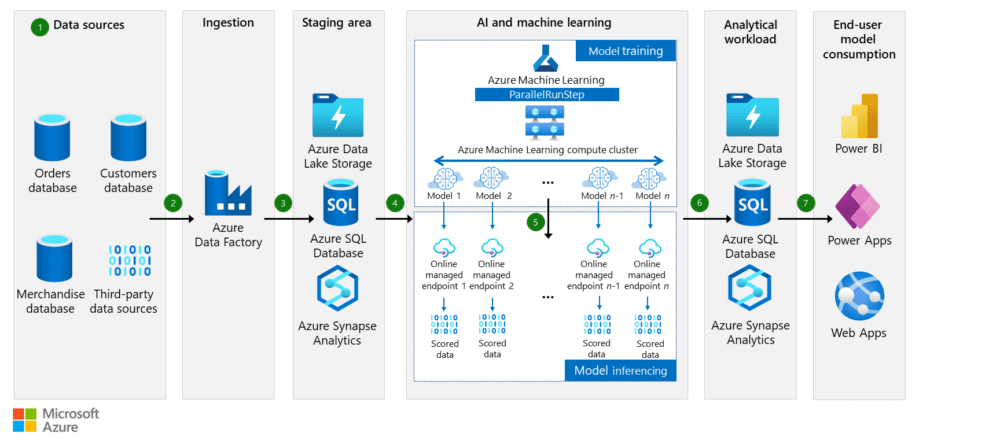
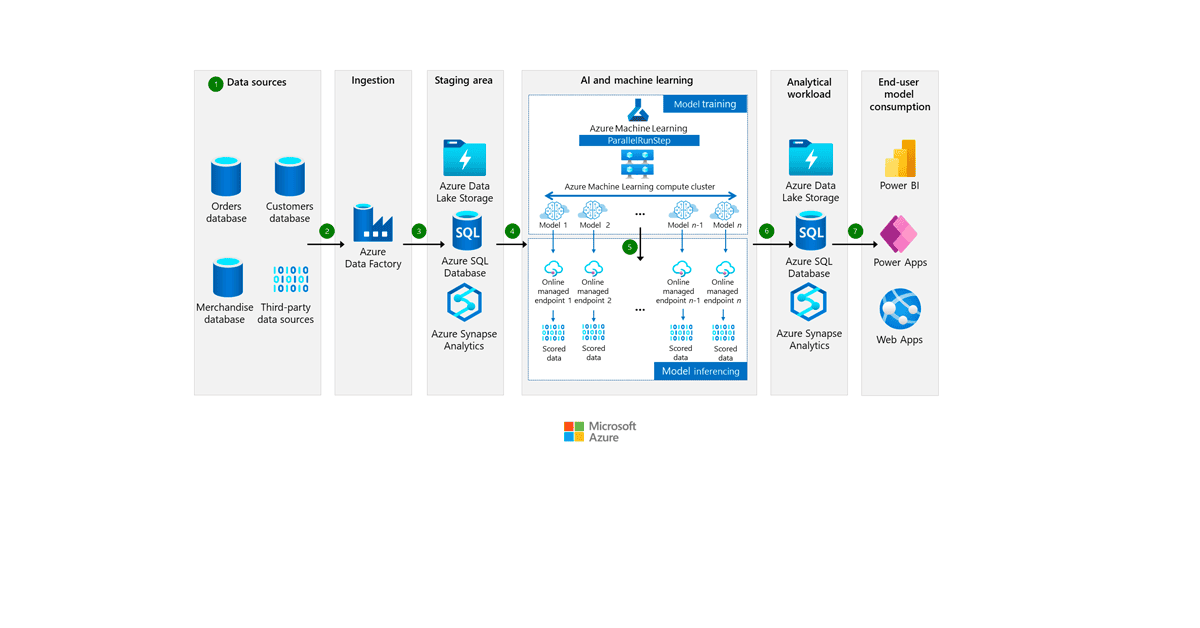
Flujo de datos
Fuentes de datos
Para predecir pedidos futuros, necesitas datos completos sobre el historial de compras de tus clientes de varias referencias en tiendas concretas, incluida información sobre preferencias y comportamiento de compra.
- Este tipo de información suele obtenerse de las bases de datos de pedidos, mercancías y clientes.
- También tienes que tener en cuenta factores externos como el tiempo, las vacaciones y los eventos. Estos datos suelen obtenerse de fuentes de terceros.
Para crear modelos de previsión de pedidos, utilizas datos en un esquema que incluye varias variables clave:
- Fecha y hora
- Ubicación de la tienda del cliente
- SKU de la mercancía
- Cantidad pedida
- Precio por unidad
- Características meteorológicas, vacaciones, eventos y otros factores externos
Analizando estos datos, puedes obtener información sobre el comportamiento del cliente y hacer recomendaciones informadas de SKU y cantidad para el próximo pedido del cliente.
Ingesta de datos
La ingesta de datos es el proceso de transferir datos de varias fuentes a un destino designado. Este proceso implica el uso de conectores específicos para cada fuente de datos y destino.
Azure Data Factory proporciona conectores que puedes utilizar para extraer datos de diversas fuentes, como bases de datos, sistemas de archivos y servicios en la nube. Estos conectores los ha creado Microsoft o proveedores externos y están diseñados para funcionar eficazmente con múltiples fuentes de datos. Por ejemplo, puedes utilizar conectores SAP para diversos escenarios de ingestión de datos SAP. Puedes utilizar el conector Snowflake para copiar datos desde Snowflake.
Área de preparación («staging area«)
El área de preparación sirve como almacén temporal entre el origen y el destino. El objetivo principal de esta área de puesta en escena es mantener los datos en un formato uniforme y estructurado mientras se someten a transformaciones o comprobaciones de calidad, antes de cargarlos en su destino.
Un formato de datos coherente es fundamental para un análisis y modelado precisos. Si consolidas y preparas los datos en un área de preparación, Azure Machine Learning puede procesarlos con mayor eficacia.
Entrenamiento de modelos de aprendizaje automático
El entrenamiento de modelos es un proceso de aprendizaje automático que implica utilizar un algoritmo para aprender patrones a partir de los datos y, en este caso, seleccionar un modelo que pueda predecir con precisión el próximo pedido de un cliente.
En esta solución, Azure Machine Learning se utiliza para gestionar todo el ciclo de vida del proyecto de aprendizaje automático, incluida la formación de modelos, el despliegue de modelos y la gestión de operaciones de aprendizaje automático (MLOps).
ParallelRunStep se utiliza para procesar grandes cantidades de datos en paralelo y crear modelos que puedan predecir el próximo pedido para cada combinación de tienda de cliente y SKU de mercancía. Puedes reducir el tiempo de procesamiento dividiendo el conjunto de datos en partes más pequeñas y procesándolas simultáneamente en varias máquinas virtuales. Puedes utilizar los clústeres informáticos de Azure Machine Learning para llevar a cabo esta distribución de las cargas de trabajo en varios nodos.
Una vez preparados los datos, Azure Machine Learning puede iniciar el proceso de entrenamiento del modelo en paralelo utilizando ParallelRunStep con una serie de modelos de previsión, como suavizado exponencial, red elástica y Prophet. Cada nodo o instancia de cálculo comienza a construir el modelo, por lo que el proceso es más eficiente y rápido.
Inferencia de modelos de aprendizaje automático
La inferencia de modelos es un proceso que utiliza un modelo de aprendizaje automático entrenado para generar predicciones para puntos de datos no vistos previamente. En esta solución, predice la cantidad de SKU de mercancía que es probable que compre un cliente.
Azure Machine Learning proporciona registros de modelos para almacenar y versionar modelos entrenados. Los registros de modelos pueden ayudarte a organizar y realizar un seguimiento de los modelos entrenados, garantizando que estén disponibles para su despliegue.
Desplegar un modelo de aprendizaje automático entrenado permite al modelo procesar nuevos datos para inferir. Te recomendamos que utilices puntos finales gestionados por Azure para el destino del despliegue. Los puntos finales facilitan la escalabilidad, el ajuste del rendimiento y la alta disponibilidad.
En este caso de uso, hay dos formas de desplegar modelos en los endpoints gestionados. La primera opción es desplegar cada modelo en su propio punto final gestionado, como se muestra en el diagrama. La segunda opción es agrupar varios modelos en uno solo y desplegarlo en un único punto final gestionado. Este último enfoque es más eficiente, ya que proporciona una forma más sencilla de desplegar y gestionar varios modelos simultáneamente.
Carga de trabajo analítica
El resultado del modelo se almacena en sistemas analíticos como Azure Synapse Analytics, Azure Data Lake o Azure SQL Database, donde también se recogen y almacenan los datos de entrada. Esta etapa facilita la disponibilidad de los resultados de la predicción para el consumo del cliente, la supervisión del modelo y el reentrenamiento de los modelos con nuevos datos para mejorar su precisión.
Cómo mostrar los datos al usuario final
Para presentar visualmente el modelo puntuado a los clientes, puedes utilizar la función Web Apps de Azure App Service, un panel de Power BI o Power Apps. Estas herramientas pueden presentar las recomendaciones para la SKU y las cantidades previstas gráficamente de forma intuitiva y atractiva.
Se avisa a los clientes de las SKU recomendadas y las cantidades previstas, para que puedan hacer pedidos de forma proactiva. Las recomendaciones pueden ayudar a agilizar el proceso de pedido, reducir la probabilidad de que se agoten las existencias y mejorar la satisfacción del cliente. Si utilizas un panel de Power BI o Power Apps, puedes ofrecer a tus clientes una experiencia de pedido fluida y eficiente.
Componentes
- Azure Synapse es un servicio de análisis empresarial que acelera la obtención de información en almacenes de datos y sistemas de big data. Azure Synapse conecta las tecnologías SQL con otros servicios Azure, como Power BI, Azure Cosmos DB y Azure Machine Learning.
- Data Factory es un servicio de integración de datos basado en la nube que automatiza el movimiento y la transformación de datos.
- Data Lake es un servicio de almacenamiento de datos ilimitado para albergar datos en diversas formas y formatos. Proporciona una fácil integración con las herramientas analíticas de Azure. Esta solución utiliza un almacén de datos local para los datos de aprendizaje automático y una caché de datos de primera calidad para entrenar el modelo de aprendizaje automático.
- Azure Machine Learning es un servicio de aprendizaje automático de nivel empresarial que facilita el desarrollo y despliegue de modelos en una amplia gama de objetivos informáticos de aprendizaje automático. Proporciona a los usuarios de todos los niveles de habilidad un diseñador de bajo código, aprendizaje automático automatizado y un entorno Jupyter Notebook alojado que admite varios entornos de desarrollo integrados.
- Los clústeres informáticos de Azure Machine Learning son estructuras informáticas gestionadas que puedes utilizar para crear fácilmente recursos informáticos de uno o varios nodos.
- Los puntos finales de Azure Machine Learning son puntos finales HTTPS a los que los clientes pueden llamar para recibir el resultado de la inferencia (puntuación) de un modelo entrenado. Un punto final proporciona un URI de puntuación estable que se autentica mediante autenticación de clave y token.
- Los pipelines de Azure Machine Learning son flujos de trabajo ejecutables de forma independiente de tareas completas de aprendizaje automático. Los pipelines pueden ayudarte a estandarizar las mejores prácticas de producción de un modelo de aprendizaje automático y mejorar la eficiencia de la construcción de modelos.
- SQL Database es un servicio de base de datos relacional totalmente gestionado y siempre actualizado, creado para la nube.
- Power BI proporciona análisis empresariales y perspectivas visualmente inmersivas e interactivas. Proporciona un rico conjunto de conectores a diversas fuentes de datos, sencillas capacidades de transformación y una sofisticada visualización.
- Power Apps es un conjunto de aplicaciones, servicios y conectores, junto con una plataforma de datos, que proporciona un entorno de desarrollo rápido para crear aplicaciones personalizadas. Puedes utilizar Power Apps para crear rápidamente aplicaciones empresariales que se conecten a tus datos. Los datos pueden almacenarse en la plataforma de datos subyacente (Microsoft Dataverse) o en varias fuentes de datos en línea y locales, como SharePoint, Microsoft 365, Dynamics 365 y SQL Server.
- Las aplicaciones web creadas con ASP.NET Core, alojadas en Azure, ofrecen ventajas competitivas sobre las alternativas tradicionales. ASP.NET Core está optimizado para las prácticas modernas de desarrollo de aplicaciones web y los escenarios de alojamiento en la nube.
Alternativas
- Azure Machine Learning proporciona modelado y despliegue de datos en esta solución. Como alternativa, puedes utilizar Azure Databricks para construir la solución con un enfoque de «primero el código». Para elegir la mejor tecnología para tu escenario, ten en cuenta las preferencias y la experiencia de tu equipo. Azure Machine Learning es una buena opción si prefieres una interfaz gráfica fácil de usar. Azure Databricks se adapta bien a los desarrolladores que desean la flexibilidad de un enfoque de «primero el código» que permite una mayor personalización.
También puedes utilizar Azure Databricks en lugar de Azure Synapse para explorar y manipular datos en esta solución. Ambas opciones proporcionan potentes herramientas de exploración y manipulación de datos. Azure Synapse proporciona un espacio de trabajo unificado que incluye funciones que facilitan la conexión e integración de datos de diversas fuentes (Azure y terceros). Azure Databricks proporciona principalmente procesamiento y análisis de datos.
Azure Synapse incluye un motor SQL que puedes utilizar para consultar y manipular datos con sintaxis SQL. Azure Databricks utiliza una interfaz basada en cuaderno que admite el uso de Python, R, Scala y SQL. - Power BI es una herramienta popular para la visualización. Grafana es otra opción viable. La principal diferencia es que Grafana es de código abierto, mientras que Power BI es un producto SaaS ofrecido por Microsoft. Si priorizas la personalización y el uso de herramientas de código abierto, Grafana es una mejor opción. Si priorizas una integración más fluida con otros productos de Microsoft, y el soporte del producto, Power BI es una mejor elección.
- En lugar de utilizar un punto final para cada modelo, puedes agrupar varios modelos en uno solo para su despliegue en un único punto final gestionado. La agrupación de modelos para su despliegue se conoce como orquestación de modelos. Los posibles inconvenientes de utilizar este enfoque incluyen una mayor complejidad, posibles conflictos entre los modelos y un mayor riesgo de tiempo de inactividad si falla el punto final único.
Detalles del escenario
Históricamente, el sector de la distribución de mercancías ha tenido dificultades para obtener información sobre el comportamiento de los clientes y sus pautas de compra, lo que dificulta ofrecer recomendaciones de productos personalizadas, mejorar la satisfacción del cliente e impulsar las ventas. Mediante el uso de la IA y el aprendizaje automático, los distribuidores de mercancías están transformando el sector.
Están adoptando la Previsión del Próximo Pedido (Next Order Forecasting · NOF), una metodología que utilizan para recomendar productos y cantidades basándose en los patrones de compra de los clientes. Esta metodología beneficia a los clientes al consolidar los pedidos y reducir los costes de transporte y logística. También permite a los distribuidores establecer contratos inteligentes con clientes habituales. Estos contratos permiten a los distribuidores recomendar proactivamente productos y cantidades con una cadencia regular, gestionar el inventario, influir en la eficiencia de la fabricación, ahorrar dinero y promover la sostenibilidad. Por ejemplo, mediante la aplicación de previsiones precisas, los distribuidores de artículos perecederos pueden gestionar niveles óptimos de inventario y, por tanto, evitar verter el exceso de existencias en vertederos.
NOF utiliza IA y algoritmos de aprendizaje automático para analizar los pedidos de los clientes y hacer recomendaciones para futuros pedidos. La arquitectura descrita aquí lleva NOF a otro nivel al permitir la previsión a nivel de SKU individual y de tienda mediante el uso de procesamiento paralelo. Esta combinación permite a las empresas prever la demanda de productos específicos en tiendas concretas. Utilizando esta metodología, puedes ofrecer a tus clientes recomendaciones personalizadas que satisfagan sus necesidades y superen sus expectativas.
Posibles casos de uso
Las organizaciones que necesitan predecir la demanda de los clientes y optimizar la gestión del inventario pueden utilizar NOF. He aquí algunos casos de uso específicos:
- Comercio electrónico. Los minoristas online pueden predecir la demanda de los clientes y recomendarles productos basándose en su historial de compras, su comportamiento de navegación y sus preferencias. Estas predicciones pueden mejorar la experiencia del cliente, aumentar las ventas y reducir los costes de logística y almacenamiento.
- Hostelería. Los hoteles y restaurantes pueden predecir la demanda de menús, bebidas y otros productos. Esto puede ayudarles a optimizar el inventario, reducir el desperdicio de alimentos y mejorar la rentabilidad.
- Sanidad. Los hospitales y clínicas pueden prever la demanda de suministros médicos, equipos y medicamentos por parte de los pacientes. Estas previsiones pueden ayudarles a reducir las roturas de inventario, evitar el exceso de existencias y optimizar los procesos de aprovisionamiento.
- Industria. Los fabricantes pueden prever la demanda de productos y materias primas, optimizar los niveles de inventario y mejorar la resistencia de la cadena de suministro.
- Energía. Las empresas energéticas pueden predecir la demanda y optimizar la generación, transmisión y distribución de energía. NOF puede ayudarles a reducir su huella de carbono y mejorar la sostenibilidad.
A tener en cuenta
Estas consideraciones implementan los pilares del Azure Well-Architected Framework, un conjunto de principios rectores que puedes utilizar para mejorar la calidad de una carga de trabajo. Para más información, consulta Microsoft Azure Well-Architected Framework.
Las tecnologías de esta solución se eligieron por su escalabilidad, disponibilidad y optimización de costes.
Seguridad
La seguridad proporciona garantías contra los ataques deliberados y el abuso de tus valiosos datos y sistemas.
La seguridad mejorada está integrada en los componentes de este escenario. Puedes utilizar la autenticación Microsoft Entra o el control de acceso basado en roles para gestionar los permisos. Considera la posibilidad de aplicar las mejores prácticas de Azure Machine Learning para la seguridad empresarial a fin de establecer los niveles de seguridad adecuados.
Azure Synapse ofrece funciones de seguridad de nivel empresarial que proporcionan aislamiento de componentes para ayudar a proteger los datos, mejorar la seguridad de la red y mejorar la protección frente a amenazas. El aislamiento de componentes puede minimizar la exposición en caso de una vulnerabilidad de seguridad. Azure Synapse también permite la ofuscación de datos para ayudar a proteger los datos personales sensibles.
Data Lake proporciona protección de datos mejorada, enmascaramiento de datos y protección contra amenazas mejorada.
Excelencia operativa
La excelencia operativa abarca los procesos de operaciones que despliegan una aplicación y la mantienen funcionando en producción. La observabilidad, la supervisión y los ajustes de diagnóstico son tres consideraciones importantes a destacar en este pilar.
La observabilidad se refiere a la capacidad de comprender cómo funciona el flujo de datos de un sistema. La monitorización es el proceso continuo de seguimiento del rendimiento de un sistema a lo largo del tiempo. Puedes supervisar métricas como el uso de la CPU, el tráfico de red y los tiempos de respuesta. Los ajustes de diagnóstico son opciones de configuración que puedes utilizar para capturar información de diagnóstico.
Sigue las directrices de MLOps para gestionar un ciclo de vida de aprendizaje automático de principio a fin que sea escalable en múltiples espacios de trabajo. Antes de desplegar tu solución en producción, asegúrate de que admite la inferencia continua con ciclos de reentrenamiento y redespliegue automatizado de modelos.
Eficiencia del rendimiento
La eficiencia del rendimiento es la capacidad de tu carga de trabajo de escalar para satisfacer las demandas de los usuarios de forma eficiente.
La mayoría de los componentes de esta arquitectura pueden escalarse hacia arriba y hacia abajo en función de los niveles de actividad de análisis. Azure Synapse proporciona escalabilidad y alto rendimiento y puede reducirse o pausarse durante niveles bajos de actividad.
Puedes escalar Azure Machine Learning en función de la cantidad de datos y de los recursos informáticos necesarios para el entrenamiento del modelo. Puedes escalar el despliegue y los recursos informáticos en función de la carga esperada y del servicio de puntuación.
Las pruebas de carga son un paso importante para garantizar la eficacia del rendimiento del modelo de aprendizaje automático. Estas pruebas implican la simulación de un alto volumen de peticiones al modelo para medir métricas como el rendimiento, el tiempo de respuesta y la utilización de recursos. Las pruebas de carga pueden ayudarte a identificar los cuellos de botella y los problemas que pueden afectar al rendimiento del modelo en un entorno de producción.
Información basada en la publicación oficial de Microsoft «Use AI to forecast customer orders«. El diagrama analizado se puede descargar de aquí en PPTX.