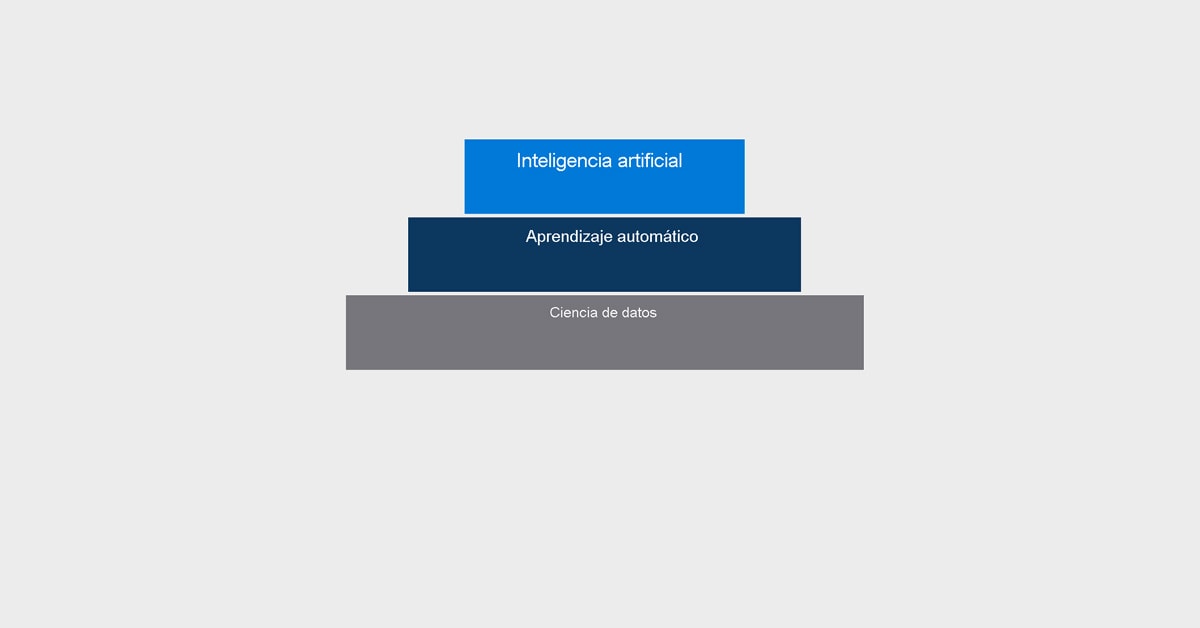
Ciencia de datos, Aprendizaje automático e Inteligencia Artificial
Tres términos relacionados con la inteligencia artificial que hay que tener claros.
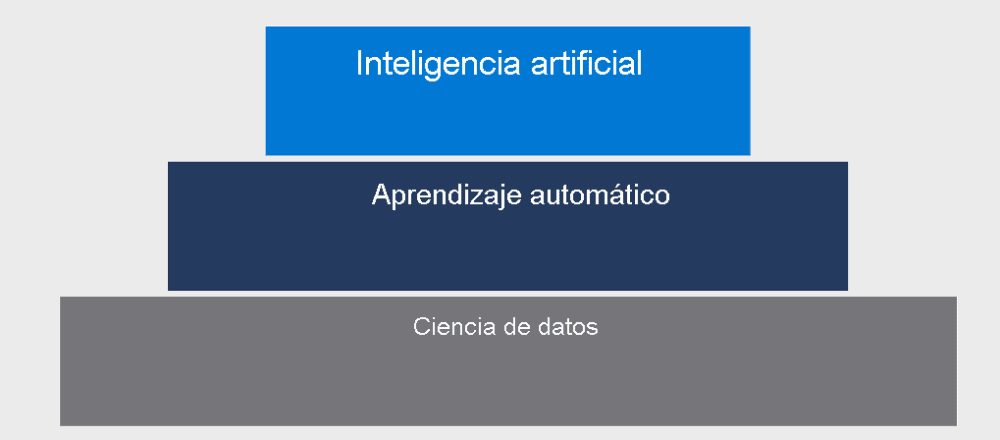
Ciencia de datos
La ciencia de datos es una materia que se centra en el procesamiento y análisis de datos, la aplicación de técnicas estadísticas para descubrir y visualizar relaciones y patrones en los datos, y la definición de modelos experimentales que ayuden a explorar esos patrones.
Por ejemplo, un científico de datos podría recopilar muestras de datos sobre la población de una especie en peligro en un área geográfica y combinarlos con datos sobre los niveles de industrialización y datos demográficos económicos de la misma área. A continuación, se pueden analizar los datos mediante técnicas estadísticas para extrapolar las muestras con el fin de comprender las tendencias y relaciones entre las actividades humanas y la vida silvestre, y probar hipótesis mediante modelos que muestren el impacto probable de la actividad humana en las especies silvestres. Al hacerlo, los científicos de datos pueden ayudar a determinar las directivas óptimas que equilibran la necesidad de bienestar económico de la población humana con la necesidad de conservación de la vida silvestre en peligro.
Machine Learning
El aprendizaje automático es un subconjunto de la ciencia de datos que se ocupa del entrenamiento y la validación de modelos predictivos. Normalmente, un científico de datos prepara los datos y, a continuación, los usa para entrenar un modelo basado en un algoritmo que aprovecha las relaciones entre las características de los datos para predecir valores para etiquetas desconocidas.
Por ejemplo, un científico de datos podría usar los datos que han recopilado para entrenar un modelo que predice el crecimiento o disminución anual de la población de una especie en función de factores como el número de sitios de anidación observados, el área de tierra designada como protegida, la población humana del área local, el volumen diario de tráfico en carreteras locales, etc. A continuación, este modelo predictivo se puede usar como herramienta para evaluar los planes de alojamiento, la infraestructura y el desarrollo industrial del área local, y evaluar su probable impacto en la vida silvestre local.
Inteligencia artificial
La inteligencia artificial normalmente (pero no siempre) se basa en el aprendizaje automático para crear software que emula una o varias características de la inteligencia humana.
Por ejemplo, el equilibrio de la necesidad de conservación de la vida silvestre frente al desarrollo económico requiere una supervisión precisa de la población de las especies en peligro protegidas. Puede que no sea factible confiar en expertos humanos que puedan identificar positivamente al animal en cuestión o supervisar un área grande durante un período de tiempo suficiente para obtener un recuento preciso. De hecho, la presencia de observadores humanos puede disuadir a los animales y evitar su detección. En este caso, se podría entrenar un modelo predictivo para analizar los datos de imagen tomados por cámaras activadas por movimiento en ubicaciones remotas y predecir si una fotografía contiene un avistamiento del animal. A continuación, el modelo se podría usar en una aplicación de software que responda a la identificación automatizada de animales para realizar un seguimiento de los avistamientos de animales en una gran área geográfica, identificando áreas con densas poblaciones de animales que pueden ser candidatas para el estado protegido.
Esta información está basada la formación de Microsoft Learn sobre Azure AI Vision.