VASA-1: Caras que hablan generadas en tiempo real con voz
foto + audio de voz = vídeo hiperrealista de una cara que habla con sincronización precisa de audio y labios, generados en tiempo real.

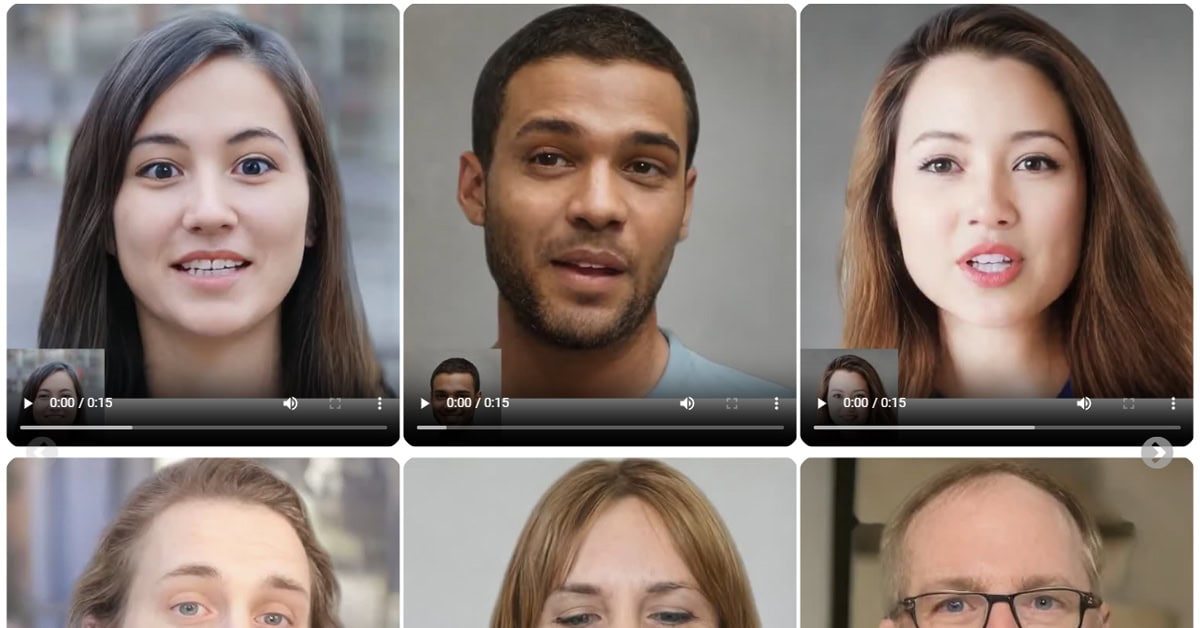
Hoy Microsoft ha anunciado VASA, un modelo de IA experimental desarrollado por su departamento de investigación que sirve para generar videos realistas a partir de una sola imagen y un audio. VASA-1, es capaz no sólo de producir movimientos labiales sincronizados con el audio, sino también de capturar matices faciales y movimientos naturales de la cabeza.
Su investigación se centra en generar capacidades visuales que den realismo a avatares virtuales de IA, con el objetivo de aplicarlo a escenarios que ayuden a las personas. Sin embargo, al igual que otras técnicas de generación de vídeo, esta también podría ser utilizada potencialmente para hacerse pasar por humanos. Por eso, aplican técnicas para la detección de deepfakes. Estos vídeos generados por este método contienen elementos identificables para anticipar su veracidad.
Aun reconociendo la posibilidad de un uso indebido, es imperativo reconocer el considerable potencial positivo que puede tener. Los beneficios -como aumentar la equidad educativa, mejorar la accesibilidad de las personas con problemas de comunicación, ofrecer compañía o apoyo terapéutico a quienes lo necesitan, entre muchos otros- subrayan la importancia de esta investigación y de otras líneas que se están desarrollando.
Microsoft solo concibe la IA de forma responsable y que tenga como objetivo mejorar el bienestar humano y no hay previsto lanzar ninguna demo online, API, producto, ni detalles adicionales de implementación hasta que estén seguros de que la tecnología se utilizará de forma responsable y de acuerdo con la normativa vigente.
¡Bienvenidos al futuro!
Información basada la «VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time» de Microsoft Research y en una publicación de LinkedIn de Alberto Pinedo Lapeña (National Technology Officer at Microsoft).